27/01/2015 Tác giả: Tim Urban (waitbutwhy.com)
(Original link: http://waitbutwhy.com/2015/01/artificial-intelligence-revolution-2.html )
Lời chú của tác giả: Đây là phần 2 trong loạt bài gồm 2 phần về AI. Phần 1 có thể xem tại đây (link tiếng Anh: http://waitbutwhy.com/2015/01/artificial-intelligence-revolution-1.html ).
—
Chúng ta đang phải đối mặt với một vấn đề vô cùng nan giải cần phải giải quyết trong một khoảng thời gian không thể xác định chính xác là bao lâu, một vấn đề mà có lẽ sẽ quyết định vận mệnh của toàn nhân loại. – Nick Bostrom
Xin chào mừng tới với Phần 2 của loạt bài “Chờ đã làm sao lại như này tôi đang đọc cái quái gì vậy tại sao chẳng ai nói gì về vụ này cả.”
Phần 1 bắt đầu với vẻ khá là vô hại, với việc đàm luận về Trí tuệ nhân tạo hẹp (ANI – AI được chuyên môn hóa ở một lĩnh vực hẹp như là thiết lập tuyến đường lái xe hay chơi cờ vua), và sự phổ biến của chúng trong thế giới của chúng ta hiện nay. Sau đó chúng ta đào sâu vào việc tại sao đi từ ANI tới Trí tuệ nhân tạo rộng – AGI (AI thông minh ở cấp độ con người một cách phổ quát) lại khó khăn tới vậy, và chúng ta đàm luận về tốc độ tăng trưởng hàm mũ của công nghệ mà chúng ta đã quan sát được từ quá khứ và từ đó rút ra được rằng AGI có lẽ không còn xa vời như chúng ta thường nghĩ. Phần 1 kết thúc bằng việc tôi tung chưởng rằng sự thật là một khi những cỗ máy này đạt tới mức độ thông minh như con người, tình hình có lẽ sẽ ngay lập tức thành như sau:




Vụ này làm chúng ta ngó chòng chọc vào màn hình, đối diện với sự dữ dội của khả năng xuất hiện Siêu trí tuệ nhân tạo – ASI (AI thông minh vượt trội so với bất kỳ con người nào trên bất kỳ lĩnh vực nào) ngay trong cuộc đời này của chúng ta, và cố gắng tưởng tượng xem chúng ta nên cảm thấy ra sao khi nghĩ về điều này. (1)
Trước khi chúng ta bắt đầu đi sâu hơn, hãy thử nhắc lại một chút về việc đối với một cỗ máy thì sở hữu siêu trí tuệ có nghĩa là như thế nào.
Một sự phân biệt mấu chốt nằm ở sự khác biệt giữa siêu trí tuệ tốc độ và siêu trí tuệ chất lượng. Thường thì, ý nghĩ đầu tiên của một người khi nghĩ tới một cỗ máy siêu thông minh là việc nó thông minh như con người nhưng có thể suy nghĩ với tốc độ nhanh hơn rất nhiều – họ có thể vẽ lên hình ảnh một cỗ máy suy nghĩ như con người nhưng nhanh hơn hàng triệu lần, tức là nó có thể xử lý một vấn đề trong vòng năm phút trong khi với con người sẽ phải mất cả thập kỷ.
Nghe thì cũng ấn tượng đấy, và ASI hẳn là sẽ nghĩ nhanh hơn bất kỳ con người nào – nhưng điều làm nên sự khác biệt chính là lợi thế của nó trong chất lượng của trí tuệ, một điều hoàn toàn khác hẳn. Điều làm con người có khả năng tư duy vượt trội so với loài linh trưởng không phải là sự khác biệt về tốc độ tư duy – mà là việc não người có những mô đun nhận thức phức tạp, cho phép những thứ như là hiểu được ngôn ngữ biểu hình phức tạp hay là lập kế hoạch dài hạn hay là lập luận trừu tượng, mà bộ não linh trưởng không thể xử lý được. Tăng tốc độ xử lý của não linh trưởng lên gấp hàng ngàn lần cũng không giúp nó đạt được tới đẳng cấp của chúng ta – ngay cả khi mất tới một thập kỷ, nó cũng không thể tìm ra cách để sử dụng những công cụ có sẵn để sắp đặt một mô hình tinh vi, trong khi con người dễ dàng làm được điều này chỉ với vài giờ đồng hồ. Có hẳn một số lượng lớn các chức năng nhận thức của con người mà một loài linh trưởng khác chỉ đơn giản là không thể nắm được, dù nó có dành ra bao nhiêu thời gian đi nữa.
Nhưng không chỉ là con linh trưởng không thể làm được những điều mà chúng ta có thể, mà não nó còn không có khả năng nhận thức là những khác biệt đó thậm chí có tồn tại – một con linh trưởng có thể dần quen với khái niệm một con người là như thế nào, hay một tòa nhà chọc trời là ra sao, nhưng nó sẽ không bao giờ có thể hiểu được rằng tòa nhà chọc trời được xây dựng bởi con người. Trong thế giới của nó, tất cả những gì to lớn như vậy cũng chỉ là một phần của tự nhiên, chấm hết, và không chỉ là nó không có khả năng xây nhà, nó còn chẳng thể nhận ra rằng có ai đó có thể xây nên một tòa nhà chọc trời. Đó là hệ quả của một khác biệt nho nhỏ trong chất lượng của trí tuệ.
Và trong thang bậc phạm vi trí tuệ mà chúng ta đang đề cập tới hôm nay, hoặc thậm chí là phạm vi trí tuệ còn hẹp hơn nữa của các loài sinh vật, cái khoảng cách giữa chất lượng trí tuệ của loài người và loài linh trưởng là siêu nhỏ. Trong một bài viết trước đây, tôi mô tả thang bậc năng lực nhận thức của sinh vật bằng một chiếc cầu thang như sau:

Để thẩm thấu được mức độ khủng khiếp của một cỗ máy siêu thông minh, hãy tưởng tượng tới bậc thang màu xanh lá cây sẫm ở phía trên loài người hai bậc. Cỗ máy này chỉ thông minh hơn một chút, nhưng mức độ chất lượng trí tuệ mà nó vượt trên chúng ta cũng đã lớn như là chúng ta đối với loài linh trưởng vậy. Và giống như việc con linh trưởng không thể nào hiểu được rằng nhà cao tầng có thể được xây lên, chúng ta cũng sẽ chẳng bao giờ có khả năng tưởng tượng ra những điều mà cỗ máy nằm trên chúng ta hai bậc có thể làm được, kể cả khi cỗ máy đó có cố giải thích cho chúng ta – chưa kể đến việc tự mình cố hiểu chúng. Và đó chỉ là ở mức hai bậc trên chúng ta thôi. Một cỗ máy nằm trên bậc thứ hai kể từ trên đỉnh thang đối với chúng ta sẽ tương tự như chúng ta đối với loài kiến – nó có thể dành hàng năm trời nỗ lực dạy cho chúng ta những điều cơ bản nhất mà nó biết mà vẫn thành công cốc.
Nhưng thứ siêu trí tuệ mà chúng ta đề cập tới ở đây lại còn là một thứ nằm quá bất kỳ thứ gì trên bậc thang đó. Nếu như một vụ bùng nổ trí tuệ xảy ra – khi mà mỗi lần một cỗ máy trở nên thông minh hơn thì nó cũng càng nhanh chóng tự tăng cường trí tuệ của bản thân lên, cho tới khi nó tăng tốc theo chiều thẳng đứng – một cỗ máy có thể mất hàng năm để đi từ bậc linh trưởng lên bậc ngay trên đó, nhưng có lẽ chỉ mất vài giờ để nhảy thêm một bước nữa khi nó đã đạt tới bậc xanh lá cây sẫm trên chúng ta hai bậc, và đến lúc nó trên chúng ta mười bậc, thì có lẽ nó đã có thể nhảy bốn bậc một lần trong mỗi giây. Đó là lý do vì sao chúng ta cần phải nhận thức rằng khả năng rất cao là rất sớm thôi, ngay sau khi cái tin gây sốt về cỗ máy đầu tiên đạt được mức AGI được tung ra, chúng ta có thể sẽ phải đối mặt với thực tế là chúng ta sẽ phải cùng tồn tại với một thứ nằm ở đây trên thang trí tuệ (hay thậm chí là cao hơn gấp vài triệu lần nữa):

Và vì chúng ta mới vừa nhận định rằng gắng hiểu một cỗ máy trên chúng ta hai bậc là hoàn toàn vô vọng, vậy thì hãy khẳng định chắc chắn một lần cho tất cả, rằng không có cách nào để biết được ASI sẽ làm gì và hệ quả của nó đối với chúng ta là gì. Tin vào điều ngược lại có nghĩa là chẳng hiểu gì về siêu trí tuệ cả.
Tiến hóa đã cải thiện bộ não sinh học một cách chậm rãi và từ từ qua hàng trăm triệu năm, và về mặt đó, nếu như loài người tạo ra một ASI, chúng ta đã vượt qua tiến hóa một cách ngoạn mục. Hoặc có thể đó là một phần của tiến hóa – có thể cách mà tiến hóa hoạt động chính là trí tuệ bước từng bước một cho tới khi nó đạt tới mức độ có thể tạo ra siêu trí tuệ, và mức độ đó như một kíp nổ – một ngưỡng châm ngòi – gây nên một vụ bùng nổ thay đổi hoàn toàn thế giới và quyết định một tương lai mới cho tất cả các sinh vật:

Và vì những lý do mà chúng ta sẽ đề cập tới sau đây, một phần lớn trong cộng đồng khoa học tin rằng vấn đề không nằm ở chỗ liệu chúng ta có đạt tới được ngưỡng châm ngòi đó không, mà là khi nào chúng ta sẽ đến đích. Một thông tin khủng đấy chứ.
Vậy thì chúng ta còn lại gì?
Thật ra thì chẳng ai trên đời này, đặc biệt là tôi, có thể nói cho bạn hay điều gì sẽ xảy ra khi chúng ta đi tới cái mốc đó. Nhưng triết gia và nhà trí tuệ nhân tạo học hàng đầu tại Oxford, Nick Bostrom, tin rằng chúng ta có thể gộp lại tất cả những hệ quả tiềm năng thành hai nhóm lớn.
Đầu tiên là, nhìn vào lịch sử thì, chúng ta có thể thấy sự sống làm việc như sau: một loài nảy ra, tồn tại một thời gian, và rồi sau một thời gian, không thể tránh khỏi được, chúng trượt khỏi chùm thăng bằng tồn tại và rơi vào tuyệt chủng –

“Tất cả các loài cuối cùng đều tuyệt chủng” cũng là một quy luật chắc chắn trong lịch sử giống như là “Tất cả mọi người cuối cùng đều chết”. Cho tới nay thì 99,9% số lượng loài đã rơi khỏi chùm cân bằng, và có vẻ rất rõ ràng là nếu như một loài nào đó bám trụ lại trên chùm này đủ lâu thì cũng chỉ còn vấn đề thời gian cho tới khi một loài nào đó, hay một cơn bão của tự nhiên, hay một thiên thể bất ngờ nào đó đá văng nó xuống. Bostrom gọi tuyệt chủng là điểm hút (attractor state) – nơi mà tất cả mọi loài đều ngả về đó và chẳng có loài nào từ đó mà trở về cả.
Và trong khi phần lớn các nhà khoa học mà tôi từng tiếp xúc đều ghi nhận rằng ASI sẽ có khả năng đẩy loài người tới bờ vực tuyệt chủng, rất nhiều người cũng tin rằng nếu như được sử dụng một cách đúng đắn, những khả năng của ASI có thể được dùng để đưa các cá nhân, và theo đó, cả tập thể loài người với tư cách một loài, tới một điểm hút thứ hai – sự bất tử loài. Bostrom tin rằng sự bất tử của loài cũng là một điểm hút y hệt như là tuyệt chủng – chúng ta sẽ đánh bại được cái chết. Vậy nên dù cho tất cả các loài từ trước tới giờ đều đã rơi khỏi chùm thăng bằng và tuyệt chủng, Bostom tin rằng chùm này có hai hướng và chỉ đơn giản là chưa từng có loài nào trên Trái đất đủ thông minh để tìm ra cách rơi về phía bên kia.

Nếu như Bostrom và những người khác đúng, và từ những điều tôi đã được đọc, có vẻ như họ thật sự như vậy, chúng ta sẽ phải tiếp nhận hai sự thật khá là gây sốc:
- Phát minh ra ASI, lần đầu tiên trong lịch sử, mở ra cơ hội để một loài có thể rơi về phía bất tử trong chùm thăng bằng.
- Phát minh ra ASI sẽ tạo nên một tác động kinh ngạc tới mức không thể tượng tượng được và sẽ đẩy loài người ra khỏi chùm thăng bằng, về hướng này hay hướng khác.
Rất có thể là khi tiến hóa đạt tới ngưỡng châm ngòi, nó sẽ chấm dứt toàn bộ liên hệ giữa loài người với chùm dây một cách triệt để và tạo nên một thế giới hoàn toàn khác, dù là có hay không còn tồn tại con người.
Có vẻ như câu hỏi duy nhất mà bất kỳ người nào cũng nên đặt ra lúc này là: Khi nào chúng ta đạt tới ngưỡng và chúng ta sẽ ngả về hướng nào khi điều đó xảy ra?
Chẳng ai biết được câu trả lời cho bất kỳ phần nào trong câu hỏi đó, nhưng kha khá những người trong số thông minh nhất đã dành hàng thập kỷ để suy nghĩ về điều đó. Chúng ta sẽ dành phần còn lại của bài viết này để tìm hiểu xem họ đã vạch ra những gì.
—
Hãy bắt đầu với phần đầu tiên của câu hỏi: Khi nào chúng ta sẽ chạm ngưỡng châm ngòi?
hay là Còn bao lâu nữa thì cỗ máy đầu tiên đạt tới mức siêu trí tuệ?
Không ngạc nhiên cho lắm, các ý kiến vô cùng đa dạng dẫn tới một cuộc tranh luận sôi nổi giữa các nhà khoa học và tư tưởng. Nhiều người trong số đó, như giáo sư Vernor Vinge, nhà khoa học Ben Goertzel, nhà đồng sáng lập Sun Microsystems Bill Joy, hay là người nổi tiếng nhất, nhà phát minh và tương lai học Ray Kurzweil, đồng tình với chuyên gia về mô hình hóa bằng máy (machine learning) Jeremy Howard khi ông đề xuất biểu đồ sau trong một buổi TED Talk:

Những người này tin rằng điều này sẽ diễn ra rất sớm – rằng có thể áp dụng luật tăng trưởng hàm mũ ở đây và mô hình hóa bằng máy, dù hiện nay chỉ diễn ra rất từ từ, sẽ bùng nổ trước khi chúng ta nhận ra trong vòng vài thập kỷ tới.
Những người khác, như nhà đồng sáng lập Microsoft Paul Allen, nhà tâm lý học Gary Marcus, nhà khoa học máy tính NYU Ernest Davis, và doanh nhân công nghệ Mitch Kapor, tin rằng những nhà tư tưởng như Kurweil đang đánh giá quá thấp tầm cỡ thực sự của thử thách và tin rằng chúng ta chưa tiến tới gần ngưỡng tới mức đó.
Đội của Kurweil sẽ phản pháo rằng điều duy nhất bị đánh giá thấp ở đây chính là sự coi thường tăng trưởng hàm mũ, và họ sẽ so sánh những người hoài nghi với những người nhìn vào những mầm mống nảy nở chậm rãi của mạng internet vào năm 1985 để tranh luận rằng nó sẽ chẳng đi tới đâu trong tương lai gần.
Những người hoài nghi có thể sẽ phản bác rằng tiến trình cần thiết để có thể tiến lên về mặt trí tuệ cũng sẽ tăng lên theo hàm mũ về độ khó với mỗi bước tiến tiếp theo, và sẽ loại trừ tính tăng theo hàm mũ của tiến bộ công nghệ. Và cứ thế.
Một nhóm thứ ba, bao gồm Nick Bostrom, tin rằng chẳng nhóm nào có cơ sở để dám chắc về mặt thời gian và ghi nhận cả hai điều rằng A) điều đó hoàn toàn có thể xảy ra trong tương lai gần và B) chẳng có gì để dám chắc về điều đó; nó cũng hoàn toàn có thể xảy ra trong một tương lai khá xa.
Những người khác, như triết gia Hubert Dreyfus, tin rằng cả ba nhóm đều quá ngây thơ khi cho rằng có cái ngưỡng đó, tranh luận rằng khả năng cao là ASI thậm chí chẳng bao giờ có thể đạt được nữa.
Vậy chúng ta có thể rút ra được gì khi xem xét tất cả những luồng quan điểm này?
Vào năm 2013, Vincent C. Müller và Nick Bostrom đã tiến hành một khảo sát với hàng trăm chuyên gia về AI trong một loạt hội thảo về câu hỏi sau: “Trong giới hạn câu hỏi này, giả định rằng những hoạt động khoa học của loài người tiếp diễn mà không bị ngáng trở nào đáng kể. Bạn cho rằng tới năm nào sẽ có khả năng (10%/50%/90%) là xuất hiện HLMI (Human-level machine intelligence – hay là AGI)?” Nó yêu cầu người tham gia ghi xuống một năm lạc quan (năm mà họ tin rằng có khả năng 10% là chúng ta đạt tới AGI), một dự đoán thực tế (năm mà họ tin rằng có 50% khả năng xuất hiện AGI – hay có thể hiểu là sau năm đó họ cho rằng khả năng tồn tại AGI là cao hơn khả năng không tồn tại), và một dự đoán an toàn (năm gần nhất mà họ có thể đoán với mức chắc chắn 90% rằng chúng ta có thể có AGI). Tổng hợp dữ liệu lại cho ta kết quả sau: (2)
Năm lạc quan trung bình(10% khả năng): 2022
Năm thực tế trung bình (50% khả năng): 2040
Năm bi quan trung bình (90% khả năng): 2075
Vậy là ở mức trung bình người tham gia nghĩ rằng chúng ta có khả năng tương đối sẽ đạt được AGI trong vòng 25 năm tới. Câu trả lời ở mức 90% trung bình vào năm 2075 có nghĩa là nếu bây giờ bạn là một thiếu niên, thì người tham gia ở mức trung bình, cùng với hơn một nửa nhóm chuyên gia về AI, khá chắc chắn rằng AGI sẽ xuất hiện trong cuộc đời bạn.
Một nghiên cứu khác được tiến hành gần đây bởi tác giả James Barrat tại Hội thảo AGI thường niên của Ben Goertzel, đã bỏ số phần trăm đi mà chỉ hỏi rằng khi nào người tham gia cho rằng chúng ta sẽ đạt tới AGI – cho tới năm 2030, năm 2050, sau năm 2100, hay là không bao giờ. Kết quả: (3)
Năm 2030: 42% tổng số người tham gia
Năm 2050: 25%
Năm 2100: 20%
Sau năm 2100: 10%
Không bao giờ: 2%
Khá là tương đồng với kết quả của Müller và Bostrom. Trong khảo sát của Barrat, hơn hai phần ba số người được hỏi tin rằng AGI sẽ xuất hiện trước năm 2050 và gần một nửa dự đoán sự xuất hiện của AGI trong vòng 15 năm tới. Cũng đáng chú ý như vậy là chỉ có 2% số người được hỏi cho rằng AGI sẽ không xuất hiện trong tương lai.
Nhưng AGI không phải là cái ngưỡng châm ngòi đã được nhắc tới, mà là ASI. Vậy những chuyên gia cho rằng tới bao giờ chúng ta sẽ đạt được ASI?
Müller và Bostrom đồng thời hỏi các chuyên gia rằng liệu họ có thấy khả năng cao là chúng ta sẽ đạt tới ASI A) trong vòng 2 năm sau khi đạt tới AGI (hay có thể hiểu là một cuộc bùng nổ trí tuệ gần như ngay lập tức), và B) trong vòng 30 năm. Kết quả là: (4)
Câu trả lời trung bình đặt cuộc chuyển hóa từ AGI tới ASI trong vòng 2 năm ở mức 10% khả năng, nhưng một cuộc chuyển hóa dài hơn trong vòng 30 năm hay ít hơn ở mức 75% khả năng.
Từ số liệu này chúng ta không biết được độ dài của quá trình chuyển hóa mà người tham gia trung bình sẽ đoán là bao nhiêu ở mức 50%, nhưng để hình dung một cách tương đối, dựa trên hai câu trả lời trên, chúng ta hãy coi rằng họ sẽ nói con số này là 20 năm. Vậy thì ý kiến trung bình – con số nằm ngay chính trung tâm của giới chuyên gia AI – tin rằng dự đoán thực tế nhất về thời điểm chúng ta đạt ngưỡng ASI là [dự đoán năm 2040 về AGI + suy đoán tương đối rằng sẽ mất 20 năm để chuyển từ AGI sang ASI] = 2060.

Đương nhiên, tất cả những số liệu trên đều chỉ đơn thuần là suy đoán, và chúng cũng chỉ đại diện cho mức trung bình của giới chuyên gia AI, nhưng nó có thể cho chúng ta thấy rằng một phần lớn những người hiểu biết nhất về lĩnh vực này sẽ đồng ý rằng 2060 là một suy đoán rất hợp lý cho sự xuất hiện của một ASI có thể thay đổi thế giới. Chỉ trong vòng 45 năm nữa thôi.
Rồi, giờ thì tới phần thứ hai của câu hỏi trên: Khi chúng ta đã đạt ngưỡng châm ngòi rồi, thì chúng ta sẽ ngả về phần nào của chùm thăng bằng?
Siêu trí tuệ sẽ mang lại quyền lực khủng khiếp – và câu hỏi quan trọng nhất cho chúng ta là:
Ai hay cái gì sẽ điều khiển quyền năng ấy, và động lực của họ là gì?
Câu trả lời sẽ quyết định liệu ASI sẽ là một công nghệ tuyệt vời không tưởng, một công nghệ tệ hại không thể hiểu nổi, hay là ở giữa khoảng đó.
Đương nhiên, giới chuyên gia lại một lần nữa bất đồng quan điểm và đang tham gia một cuộc tranh luận rất sôi nổi về câu trả lời cho câu hỏi đó. Bản khảo sát của Müller và Bostrom cũng yêu cầu người tham gia gán một con số khả năng cho những tác động có thể có của AGI đối với nhân loại và câu trả lời trung bình là có 52% khả năng rằng kết quả sẽ hoặc là tốt hoặc là cực kỳ tốt và 31% khả năng rằng kết quả sẽ hoặc là xấu hoặc là cực kỳ xấu. Đối với một kết quả trung dung thì tỷ lệ trung bình chỉ là 17%. Nói như vậy nghĩa là những người biết nhiều nhất về điều này khá chắc rằng nó sẽ là một chấn động lớn. Cũng cần chú ý rằng những con số này là dành cho phát minh ra AGI – nếu như câu hỏi là về ASI, tôi tin rằng tỷ lệ trung bình cho kết quả trung dung sẽ còn thấp hơn nữa.
Trước khi chúng ta đào sâu hơn vào vấn đề hệ quả tốt hay xấu, hãy thử kết hợp hai phần “bao giờ nó sẽ xảy ra?” và phần “nó sẽ tốt hay xấu?” thành một biểu đồ tổng hợp các góc nhìn của những chuyên gia phù hợp nhất:

Chúng ta sẽ bàn kỹ hơn về những quan điểm trong Khu chính trong ít phút nữa, nhưng trước tiên – bạn ngả về phía nào? Thực ra tôi biết rõ bạn nghĩ ra sao, vì tôi cũng đã từng nghĩ tương tự như bạn trước khi tìm hiểu về chủ đề này. Một số lý do mà phần lớn mọi người ít khi nghĩ về vấn đề này:
- Như đã được nhắc đến ở Phần 1, phim ảnh khá là dễ gây hiểu lầm khi đưa ra những viễn cảnh không thực tế về AI khiến chúng ta cảm thấy như AI không phải là vấn đề gì nghiêm trọng lắm. James Barrat so sánh tình huống này với phản ứng của chúng ta nếu như Trung tâm Kiểm soát dịch bệnh đưa ra một thông cáo nghiêm túc về nguy cơ xuất hiện ma cà rồng trong tương lai. (5)
- Do một thứ gọi là thiên kiến nhận thức (cognitive biases), chúng ta thường khó tin một điều gì đó là thật cho tới khi thấy bằng chứng. Tôi chắc rằng những nhà khoa học máy tính vào năm 1988 thường xuyên trao đổi về tầm ảnh hưởng của mạng internet trong tương lai, nhưng đại chúng có lẽ chẳng thật sự nghĩ là nó sẽ thay đổi cuộc sống của mình cho tới khi nó thật sự thay đổi cuộc sống của chúng ta. Một phần lý do là vì máy tính không thể làm được những thứ như vậy vào năm 1988, nên người ta nhìn vào máy tính và nghĩ, “Thật sao? Cái thứ này sẽ làm thay đổi cuộc sống á?” Trí tưởng tượng của họ bị hạn chế bởi những kinh nghiệm cá nhân về một chiếc máy tính, làm cho việc tưởng tượng máy tính có thể trở nên như thế nào biến thành cực kỳ khó khăn. Điều tương tự đang diễn ra với AI. Chúng ta nghe rằng có thể nó sẽ là một thứ rất lớn lao, nhưng vì nó chưa xảy ra, và vì trải nghiệm của chúng ta với những AI khá thiếu khả năng trong thế giới hiện nay, chúng ta rất khó thật sự tin rằng chúng sẽ thay đổi thế giới một cách đáng kinh ngạc. Và thiên kiến đó là thứ các chuyên gia đang phải đối mặt khi họ nỗ lực tìm đủ mọi cách để lôi kéo sự chú ý của chúng ta giữa hàng loạt những tiếng ồn của cuộc sống hàng ngày của mỗi người.
- Kể cả khi chúng ta tin vào điều này – có bao nhiêu lần trong ngày hôm nay bạn nghĩ qua rằng rồi bạn sẽ không tồn tại trong phần lớn thời gian của vĩnh cửu? Không nhiều lắm, đúng không? Kể cả khi nó là một sự thật dữ dội hơn nhiều bất kỳ thứ gì bạn đang làm ngày hôm nay? Đó là do não của chúng ta thường tập trung vào những thứ nhỏ nhặt trong cuộc sống thường nhật, bất kể tình trạng dài hạn mà chúng ta đang phải đối mặt có điên rồ đến thế nào. Đó đơn giản chỉ là cách mà não chúng ta hoạt động mà thôi.
Một trong những mục tiêu của hai bài viết này là nhằm kéo bạn ra khỏi Khu Tôi Muốn Nghĩ Về Những Chuyện Khác Hơn và chuyển sang một trong những Khu của chuyên gia, kể cả khi bạn chỉ đứng ở điểm giao nhau của hai đường chấm trong hình vuông phía trên, hoàn toàn không chắc chắn về bất kì cái gì.
Trong quá tình nghiên cứu, tôi đã bắt gặp hàng tá các luồng quan điểm khác nhau về chủ đề này, nhưng tôi mau chóng chú ý rằng phần lớn các quan điểm nằm trong một khu vực mà tôi gọi là Khu chính, cụ thể hơn, hơn ba phần tư số chuyên gia rơi vào trong hai Phân khu nhỏ trong Khu chính.

Chúng ta sẽ đào sâu vào cả hai phân khu này. Hãy bắt đầu với điều vui vẻ hơn –
Tại sao tương lai có thể là một giấc mơ tuyệt vời nhất với chúng ta
Khi tôi tìm hiểu về thế giới AI, tôi thấy có một số lượng lớn tới đáng kinh ngạc những người đứng ở vị trí này:

Những người sống trong Góc Tự Tin như muốn nổ tung vì hào hứng. Họ hướng tầm nhìn về phía vui vẻ của chùm thăng bằng và tin rằng đó là nơi tất cả chúng ta đều đang đi tới. Đối với họ, tương lai là tất cả những gì họ có thể mong đợi, và nó sẽ tới vừa kịp lúc.
Điều phân biệt họ với những nhà tư tưởng khác mà chúng ta sẽ bàn tới sau không phải là khát khao về một chiều hướng hạnh phúc của tương lai – mà là sự tự tin rằng đó là nơi chúng ta sẽ tới.
Khởi nguồn của sự tự tin này thì lại còn phải xem xét. Những nhà phê bình tin rằng nó đến từ một sự hào hứng đến mù quáng làm cho họ lờ tịt đi hoặc phủ nhận những hệ quả tiêu cực có thể xảy ra. Nhưng những người tin tưởng thì cho rằng quả là ngây thơ khi vẽ ra một viễn cảnh của ngày tận thế trong khi nhìn một cách tổng quát, công nghệ đã và có lẽ sẽ tiếp tục giúp đỡ chúng ta hơn là làm hại chúng ta.
Chúng ta sẽ nói về cả hai phía, và bạn có thể tự đưa ra quan điểm của mình trong lúc đọc bài, nhưng trong phần này, hãy đặt sự nghi ngại sang một bên và thử đưa mình nhìn vào những điều hay ho có thể xảy ra ở phần này của chùm thăng bằng – và gắng tiếp nhận sự thật rằng những điều mà bạn đang đọc hoàn toàn có thể xảy ra. Nếu như bạn cho một người ở thời săn bắt hái lượm xem thế giới có nơi trú ẩn trong nhà thoải mái tiện nghi, công nghệ và sự dồi dào của cải vật chất, cảnh đó sẽ giống như là phép thuật viễn tưởng đối với anh ta – chúng ta cần phải thật khiêm tốn để ghi nhận rằng hoàn toàn có thể đây sẽ là một chuyển biến vĩ đại tương tự trong tương lai chúng ta.
Nick Bostrom mô tả ba cách mà một hệ thống AI siêu trí tuệ có thể hoạt động: (6)
- Như một Kẻ-biết-tuốt, trả lời gần như bất kỳ câu hỏi nào được đặt ra cho nó một cách chuẩn xác, bao gồm cả những câu hỏi phức tạp mà loài người khó có thể trả lời một cách dễ dàng: – như là Làm thế nào để sản xuất một động cơ xe hơi hiệu suất cao hơn? Google là một dạng kẻ-biết-tuốt thô sơ.
- Như một Thần đèn, thi hành mọi mệnh lệnh bậc cao được đưa ra cho nó – Sử dụng một máy lắp ráp phân tử để xây dựng một động cơ xe hơi mới với hiệu suất cao hơn – và rồi chờ đợi mệnh lệnh tiếp theo.
- Như một Đấng tối cao, được đưa cho những mục tiêu mở chung chung và được cho phép vận hành tự do trong thế giới, tự đưa ra những quyết định cho chính nó để tiến hành một cách tốt nhất – Tạo ra một cách nhanh hơn, rẻ hơn và an toàn hơn xe hơi để con người có thể di chuyển một cách riêng tư.
Những câu hỏi này có vẻ phức tạp đối với chúng ta, nhưng đối với siêu trí tuệ thì cũng chỉ giống như có ai đó hỏi chúng ta cách xử lý tình huống “Bút chì của tôi rơi khỏi cái bàn”, mà bạn sẽ xử lý bằng cách nhặt nó lên và đặt nó lại trên bàn.
Eliezer Yudkowsky, một người cư trú tại Đường E Ngại trên biểu đồ phía trên của chúng ta, đã tóm lại một cách tuyệt vời:
| Không có vấn đề nào là khó khăn, chỉ có những vấn đề khó đối với một mức độ nhất định của trí tuệ. Tiến thêm một bước nhỏ [trên thang trí tuệ], và một vài vấn đề sẽ bất chợt chuyển từ “bất khả thi” sang “hiển nhiên.” Tiến thêm một bước đủ lớn và tất cả bỗng đều trở thành hiển nhiên. (7) |
Có rất nhiều nhà khoa học, nhà phát minh và doanh nhân đầy nhiệt huyết cư ngụ ở Góc Tự Tin – nhưng để có một chuyến du hành tới nơi tươi sáng nhất trong chân trời AI, chỉ có một người mà chúng ta muốn mời làm hướng dẫn viên.
Ray Kurzweil là một nhân vật gây phân cực mạnh mẽ. Trong quá trình đọc, tôi đã thấy tất cả các quan điểm từ tôn thờ ông và tư tưởng của ông như Chúa cho tới sự khinh miệt rõ ràng. Những quan điểm khác thì nằm đâu đó trong khoảng giữa – tác giả Douglas Hofstadter, khi thảo luận về những ý tưởng trong sách của Kurweil, đã diễn đạt rằng “như thể là bạn vừa ăn một đống thức ăn tuyệt hảo trộn lẫn với phân chó và bạn chẳng thế phân biết được cái gì tốt hay tệ nữa.”
Dù bạn có thích những ý tưởng của ông hay không, tất cả đều đồng tình rằng Kurzweil rất ấn tượng. Ông bắt đầu sáng chế từ thời thiếu niên và trong những thập niên sau đó, ông đã mang lại một số sáng chế mang tính đột phá, bao gồm máy quét phẳng (flatbed scanner) đầu tiên, máy quét đầu tiên có thể chuyển văn tự thành ngôn ngữ nói (giúp người mù có thể đọc được chữ viết thông thường), đàn synthesizer đầu tiên (chiếc đàn piano điện thật sự đầu tiên), và máy nhận diện ngôn ngữ nói với vốn từ rộng được quảng bá thương mại rộng rãi đầu tiên. Ông cũng là tác giả của năm cuốn sách bán chạy nhất nước. Ông nổi tiếng bởi những dự đoán của mình và có một thành tích dự đoán trúng tương đối cao – bao gồm dự đoán từ những năm cuối thập kỷ 80, thời kỳ mà mạng internet vẫn là một thứ bí hiểm, rằng nó rồi sẽ trở thành một hiện tượng toàn cầu. Kurzweil đã được gọi là “thiên tài không ngừng nghỉ” bởi tờ Thời Báo Phố Wall, “cỗ máy tư duy tối thượng” bởi Forbes, “ người kế thừa xứng đáng của Edison” bởi tạp chí Inc., và “người giỏi nhất tôi biết về dự đoán tương lai của trí tuệ nhân tạo” bới Bill Gates. (9) Vào năm 2012, nhà đồng sáng lập Google Larry Page đã tiếp xúc với Kurzweil và đề nghị ông làm việc với tư cách giám đốc kỹ thuật của Google. Vào năm 2011, ông đã đống sáng lập ra đại học Singularity, được tổ chức bởi NASA và được tài trợ một phần bới Google. Một cuộc đời không tệ.
Đoạn tiểu sử này khá là quan trọng. Khi Kurzweil trình bày dự đoán của ông về tương lai, nghe ông cứ như thể đang phê cần vậy, và điều điên rồ ở đây là sự thật không hề như thế – ông là một người hết sức thông minh, hiểu biết và hoàn toàn sáng suốt. Bạn có thể nghĩ rằng ông đã sai khi dự đoán về tương lai, nhưng ông không phải là một kẻ đần độn. Biết rằng ông là một nhân vật đáng tin cậy khiến tôi thấy vui sướng, bởi khi tôi đã biết được những dự đoán về tương lai của ông, tôi cực kỳ mong là ông đúng. Và bạn cũng vậy. Khi bạn nghe về những dự đoán của Kurzweil, được đồng tình bởi những nhà tư tưởng thuộc Góc Tự Tin như Peter Diamandis và Ben Goertzel, bạn sẽ thấy không khó hiểu tại sao ông lại thu thập được một lượng lớn những người ủng hộ nhiệt tình đến vậy – họ được gọi là những “singularitarian”. Ông nghĩ rằng tương lai sẽ như thế này:
Dòng thời gian
Kurzweil tin rằng máy tính sẽ đạt được mốc AGI vào năm 2029 và rằng tới năm 2045, chúng ta không chỉ có được ASI, mà còn có một thế giới mới không tưởng tượng nổi – thời điểm mà ông gọi là điểm dị biệt (singularity). Dòng thời gian mà ông đưa ra từng bị coi là quá sức lạc quan, và cho tới giờ nhiều người vẫn coi nó như vậy, nhưng trong 15 năm trở lại đây, những tiến trình đạt được về các hệ thống ANI đã đưa giới chuyên gia AI đã trở nên đông đảo hơn tới gần hơn với dòng thời gian của Kurzweil. Những dự đoán của ông vẫn là tương đối tham vọng đối với một người tham gia trung bình trong khảo sát của Müller và Bostrom (AGI vào năm 2040, ASI vào năm 2060), nhưng cũng không hẳn là cách xa lắm.
Mô tả của Kurzweil về điểm dị biệt năm 2045 là nó sẽ xảy ra do ba cuộc cách mạng đồng thời trong công nghệ sinh học, công nghệ nano, và mạnh mẽ hơn hết, là AI.
Trước khi chúng ta đi tiếp – công nghệ nano xuất hiện trong phần lớn mọi thứ bạn đọc về tương lai của AI, vậy nên hãy lướt qua ô màu xanh này trong một phút để chúng ta có thể bàn luận về nó –
| Ô xanh về Công nghệ Nano
Công nghệ Nano là từ dùng để chỉ công nghệ được sử dụng để xử lý vật chất với kích cỡ từ 1 tới 100 nano mét. Một nano mét bằng một phần tỷ mét, hay là một phần triệu mili mét, và giới hạn từ 1 tới 100 này bao gồm vi rút (khoảng 100 nm), DNA (rộng cỡ 10 nm), và những thứ nhỏ như các phân tử lớn ví dụ như hemoglobin (5 nm) và phân tử cỡ trung như glucose (1 nm). Nếu như/khi chúng ta chinh phục được công nghệ nano, bước tiếp theo sẽ là khả năng điều khiển những nguyên tử độc lập, với kích cỡ chỉ nhỏ hơn 1 bậc (khoảng 0.1 nm).
Để hiểu được thử thách của loài người khi xử lý những vật chất nhỏ cỡ này, hãy thử xem xét điều tương tự ở quy mô lớn hơn. Trạm Vũ trụ Quốc tế nằm ở vị trí 268 dặm (431 km) phía trên Trái đất. Nếu như con người là những người khổng lồ lớn đến độ đầu chúng ta với tới được trạm ISS, chúng ta sẽ lớn hơn mức hiện nay là 250,000 lần. Nếu như bạn phóng đại khoảng 1 – 100 nm của công nghệ nano gấp 250,00 lần, bạn sẽ đạt mức 0.25 mm – 2.5 cm. Vậy công nghệ nano tương đương với việc một người khổng lồ cao như trạm ISS gắng tìm cách dựng những đồ vật phức tạp một cách tỉ mỉ, sử dụng vật liệu nằm trong khoảng kích cỡ từ một hạt cát cho tới một nhãn cầu. Để đạt được tới ngưỡng tiếp theo – điều khiển những nguyên tử riêng biệt – người khổng lồ sẽ phải cẩn thận sắp đặt các vật thể cỡ 1/40 mm – nhỏ tới mức những người cỡ bình thường sẽ cần tới kính hiển vi để nhìn thấy chúng.
Công nghệ nano đã được thảo luận lần đầu tiên bởi Richard Feynman trong một bài nói chuyện năm 1959, khi ông giải thích rằng: “Nguyên lý của vật lý, theo những gì tôi được biết, không phủ định khả năng thao tác ở cấp phân tử. Theo lý thuyết thì một nhà vật lý có thể tổng hợp bất kỳ chất hóa học nào mà nhà hóa học viết ra… Bằng cách nào? Đặt những phân tử xuống những nơi mà nhà hóa học chỉ, và rồi bạn có thể tạo ra chất đó.” Đơn giản là như vậy thôi. Nếu như bạn có thể tìm ra cách di chuyển những phân tử hay nguyên tử riêng lẻ, bạn có thể tạo ra mọi thứ theo đúng nghĩa đen.
Công nghệ nano đã trở thành một lĩnh vực nghiêm túc lần đầu tiên vào năm 1986, khi kỹ sư Eric Drexler đặt nền móng cho nó bằng cuốn tài liệu hội thảo Kỹ thuật Tạo tác, nhưng Drexler cho rằng những người muốn hiểu biết nhiều hơn về những tư tưởng hiện đại nhất trong công nghệ nano nên đọc cuốn sách được xuất bản năm 2013 của ông, Sự dồi dào căn bản (Radical Abundance).
| Ô xanh hơn về Chất nhờn xám (Gray Goo)
Chúng ta hiện nay đang ở một ghi chú bên trong một ghi chú. Thật thú vị quá đi mất!
Dù sao thì, tôi đưa bạn tới đây vì đây là một phần hết sức kém vui về kiến thức công nghệ nano mà tôi cần phải cho bạn biết. Trong một phiên bản cũ hơn của học thuyết công nghệ nano, một phương án được đề xuất cho dây chuyền nano bao gồm việc tạo ra hàng tỷ tỷ những robot nano (nanobot) cùng phối hợp để xây dựng thứ gì đó. Một cách để tạo ra những nanobot này sẽ là làm một chiếc có khả năng tự nhân đôi và rồi để quá trình đó biến một con thành hai con, rồi hai con đó biến thành bốn, bốn biến thành tám, và trong vòng khoảng 1 ngày, sẽ có khoảng vài tỷ tỷ con sẵn sàng vào vị trí. Đó là sức mạnh của tăng trưởng hàm mũ. Thông minh quá phải không?
Thông minh cho tới khi chính việc đó tạo ra một thảm họa tận thế quy mô hành tinh do tai nạn. Vấn đề là chính sức mạnh của tăng trưởng hàm mũ đã giúp tạo ra hàng tỷ tỷ con nanobot cũng làm cho quá trình tự nhân đôi là một khả năng vô cùng đáng sợ. Bởi vì điều gì sẽ xảy ra nếu hệ thống bị lỗi, và thay vì ngừng khi đạt tới mức một tỷ tỷ nanobot, nó lại cứ tiếp tục nhân đôi? Những con robot nano sẽ được thiết kế để “ăn” bất kỳ thứ gì có gốc carbon nhằm cung cấp cho quá trình nhân đôi, và không vui vẻ gì lắm, tất cả các sinh thể đều có gốc carbon. Tập sinh quyển của Trái đất chứa khoảng 10^45 nguyên tử carbon. Một nanobot sẽ chứa khoảng 10^6 nguyên tử carbon, vậy thì 10^39 nanobot sẽ hấp thụ toàn bộ sinh thể trên trái đất, và điều này sẽ xảy ra sau khoảng 130 lần nhân đôi (2^130 xấp xỉ 10^39), khi một biển các nanobot (đó chính là chất nhờn xám) tràn ra khắp hành tinh. Các nhà khoa học nghĩ rằng một nanobot có thể nhân đôi trong khoảng 100 giây, tức là lỗi nhỏ này sẽ tiêu diệt toàn bộ sự sống trên Trái đất một cách không dễ chịu gì trong chỉ có 3.5 giờ đồng hồ.
Một tình huống tồi tệ hơn – là nếu như một tên khủng bố bằng cách nào đó có được công nghệ nano và có đủ kiến thức để lập trình chúng, hắn ta có thể trước tiên tạo ra vài tỷ con rồi lập trình chúng để chúng lặng lẽ tràn ra khắp hành tinh mà không bị phát hiện. Rồi sau đó, chúng đồng loạt phát động tấn công, và rồi chỉ mất 90 phút để chúng hấp thu tất cả mọi thứ – và khi chúng lan tới mọi ngõ ngách như vậy thì chẳng có cách nào để đối phó được với chúng.
Trong khi câu chuyện kinh dị này đã được thảo luận rộng rãi trong nhiều năm, thì tin tốt là nó có thể chỉ là thái quá – Eric Drexler, cha đẻ của thuật ngữ “chất nhờn xám,” gửi cho tôi một email sau bài viết này về suy nghĩ của ông về viễn cảnh chất nhờn xám: “Mọi người đều thích những câu chuyện đáng sợ, và vụ này cũng giống như vụ zombie vậy. Bản thân ý tưởng đó đã muốn ăn mòn não rồi.” |
Một khi chúng ta đã chinh phục được công nghệ nano, chúng ta có thể dùng nó để làm ra những sản phẩm công nghệ, quần áo, đồ ăn, một loạt các sản phẩm liên quan tới sinh thể – như là tế bào máu nhân tạo, vi rút hay các cỗ máy phá hủy tế bào ung thư, các mô cơ, vân vân – bất kỳ thứ gì. Và trong một thế giới sử dụng công nghệ nano, chi phí của một vật liệu không còn phụ thuộc vào độ hiếm của nó hay mức độ khó khăn của quy trình sản xuất, mà thay vào đó là mức độ phức tạp của cấu tạo nguyên tử của nó. Trong một thế giới có công nghệ nano, một viên kim cương có thể rẻ hơn cả một cục tẩy bút chì.
Chúng ta chưa đi được tới đó. Và cũng không rõ liệu chúng ta đang đánh giá quá thấp, hay quá cao, độ khó của hành trình đi tới đó. Nhưng chúng ta có vẻ không ở quá xa ngày đó. Kurweil dự đoán là chúng ta sẽ đạt được điều này vào năm 2020. (11) Các chính phủ biết rằng công nghệ nano có thể sẽ là một bước tiến làm rung chuyển thế giới, và họ đã đầu tư hàng tỷ đô vào việc nghiên cứu công nghệ nano (Mỹ, châu Âu và Nhật bản đã đầu tư tổng cộng là 5 tỷ đô). (12)
Chỉ xem xét tới khả năng một máy tính siêu trí tuệ có thể tiếp cận một dây chuyền sản xuất nano mạnh mẽ đã là quá điên rồ. Nhưng công nghệ nano là thứ mà chúng ta đã kiến tạo ra, và đang trong quá trình đạt tới nó, và vì tất cả những gì chúng ta có thể làm được chỉ là một trò đùa với một hệ thống ASI, chúng ta cần mặc định rằng ASI sẽ còn nghĩ tới những công nghệ còn quyền năng hơn và tiến bộ đến mức vượt quá khả năng tiếp thu của bộ não người. Vì lý do này, khi xem xét viễn cảnh “Nếu cuộc cách mạng AI lại hóa ra quá lợi cho chúng ta”, gần như là không thể đánh giá quá cao tầm vóc của những gì có thể diễn ra – vậy nếu như những dự đoán về tương lai của ASI có vẻ như quá xa vời, hãy nhớ rằng chúng có thể diễn biến theo những cách mà chúng ta thậm chí chẳng thể tưởng tượng ra nổi. Khả năng cao nhất là, não của chúng ta thậm chí còn chẳng có năng lực để mà dự đoán những điều có thể xảy ra được nữa. |
Những điều AI có thể làm cho chúng ta

Được trang bị bởi siêu trí tuệ và tất cả những công nghệ mà siêu trí tuệ sẽ biết cách tạo ra, ASI có lẽ sẽ có khả năng giải quyết mọi vấn đề của nhân loại. Sự nóng lên toàn cầu? ASI có thể trước tiên giảm phát thải CO2 bằng cách vạch ra những cách tốt hơn nhiều để tạo ra năng lượng mà không cần tới than hóa thạch. Rồi thì nó có thể tạo ra những cách vô cùng tiên tiến để bắt đầu loại bỏ CO2 dư thừa ra khỏi khí quyển. Ung thư hay những dịch bệnh khác? Không là gì đối với ASI – sức khỏe và thuốc men sẽ được cải cách đến độ không thể tưởng tượng nổi. Nạn đói? ASI có thể sử dụng những thứ như là công nghệ nano để tạo ra thịt từ không khí với cấu tạo phân tử tương tự như thịt thật – nói cách khác đó chính là thịt thật. Công nghệ nano có thể biến một đống rác thành một tảng thịt lớn tươi rói hay những loại thực phẩm khác (mà không hẳn phải có dạng như đồ ăn bình thường – cứ tưởng tượng một khối táo thập phương lớn) – và phân phát lượng thức ăn này đến khắp mọi nơi trên thế giới bằng công nghệ giao thông tối tân. Đương nhiên, điều này cũng sẽ rất tuyệt vời đối với các loài động vật, vì chúng sẽ không bị giết hại bởi con người nhiều lắm nữa, và ASI cũng có thể làm rất nhiều điều khác để bảo tồn những loài đang trên đà tuyệt chủng và thậm chí có thể mang những loài đã tuyệt chủng trở lại bằng cách làm việc với những DNA được bảo lưu. ASI cũng có thể giải quyết được những vấn đề vĩ mô phức tạp nhất – những cuộc tranh luận quanh việc nền kinh tế nên được vận hành ra sao và thương mại thế giới được thúc đẩy thế nào, ngay cả những vấn đề tù mù nhất về triết học hay đạo đức – cũng sẽ đều hết sức hiển nhiên đến mức đáng sợ với ASI.
Nhưng có một điều mà ASI có thể làm cho chúng ta, vĩ đại cực kỳ, và đọc về nó đã thay đổi tất cả hiểu biết mà tôi tin là tôi có về mọi điều:
ASI có thể cho phép chúng ta chinh phục cái chết.
Một vài tháng trước, tôi đã nhắc tới việc tôi ghen tị thế nào với những nền văn minh tân tiến tương lai, khi mà cái chết đã bị chinh phục, chưa từng thoáng nghĩ tới khả năng sau đó tôi có thể viết một bài làm cho tôi thực lòng tin tưởng rằng đó là một điều mà loài người có thể đạt được trong thời gian tôi còn sống. Nhưng đọc về AI sẽ làm cho bạn suy nghĩ lại về mọi thứ mà bạn nghĩ bạn chắc chắn là bạn đúng – bao gồm cả về cái chết.
Tiến hóa chẳng có lý do mật thiết nào để kéo dài thời gian sống của sinh thể hơn mức hiện tại. Nếu chúng ta sống đủ lâu để sinh sản và nuôi con cái tới một độ tuổi mà chúng có thể tự bảo vệ mình, như thế đã là đủ đối với tiến hóa – nhìn từ quan điểm của tiến hóa, một loài có thể tiếp tục duy trì với thời gian sống của sinh thể là hơn 30 năm, vậy nên không có lý do gì để cho những cá thể dị biệt với một đời sống được kéo dài hơn mức thông thường có được lợi thế trong quá trình chọn lọc tự nhiên. Kết quả là, chúng ta được W.B. Yeats mô tả như “những linh hồn bị trói buộc vào một sinh vật đang chết dần.” (13) Chẳng vui vẻ chút nào.
Và bởi vì tất cả mọi người trước giờ vẫn chết, chúng ta sống với mặc định “cái chết và sự trả nợ”, hay là cái chết là điều không thể tránh khỏi. Chúng ta nghĩ về việc già đi giống như là thời gian vậy – cả hai đều chuyển động và không gì ngăn được chúng . Nhưng mặc định đó là sai lấm. Richard Feynman viết rằng:
| Một trong những thứ đáng chú ý nhất trong tất cả những ngành khoa học sinh học là không có bằng chứng nào cho sự cần thiết của cái chết. Nếu bạn nói rằng chúng ta muốn tạo ra động cơ vĩnh cửu, thì chúng ta đã tìm ra được đủ các quy luật vật lý để nhận thấy rằng hoặc điều đó là bất khả, hoặc là các quy luật đó sai. Nhưng không có gì trong các khám phá của ngành sinh học cho thấy sự cần thiết của cái chết. Điều này làm cho tôi nghĩ rằng có lẽ nó là hoàn toàn có thể tránh được và chỉ là vấn đề thời gian cho tới khi những nhà sinh vật học tìm ra nguyên nhân gây ra rắc rối này và dịch bệnh toàn cầu tệ hại này hay là sự hữu hạn của cơ thể người rồi sẽ được chữa khỏi. |
Sự thật là, sự lão hóa không hề bị gắn chặt vời thời gian. Thời gian phải tiếp tục tịnh tiến, nhưng sự lão hóa thì không hẳn như vậy. Nếu bạn thử nghĩ về điều đó thì thực ra nó rất hợp lý. Sự lão hóa chính là những vật chất cấu tạo nên cơ thể bị cũ mòn đi. Một chiếc xe ô tô qua thời gian cũng bị cũ mòn đi – nhưng nó có nhất thiết bị lão hóa không? Nếu như bạn sửa chữa hoặc thay thế những phần của ô tô khi chúng bắt đầu cũ mòn một cách hoàn hảo, chiếc xe sẽ chạy mãi. Cơ thể người cũng không khác gì – chỉ là phức tạp hơn.
Kurzweil trình bày về những robot nano có trí tuệ được kết nổi bởi wifi trong hệ tuần hoàn, chúng có thể thực hiện vô số các nhiệm vụ vì sức khỏe con người bao gồm việc thay thế thường xuyên những tế bào đã cũ ở bất kì phần nào của cơ thể. Nếu được hoàn thiện, quá trình này (hoặc một quá trình khác còn thông minh hơn mà ASI có thể đề xuất ra) sẽ không những chỉ giữ cho cơ thể khỏe mạnh, nó thậm chí còn đảo ngược quá trình lão hóa. Sự khác biệt giữa một cơ thể 60 tuổi và một cơ thể 30 tuổi chỉ là một loạt các tính chất vật lý hoàn toàn có thể thay đổi được nếu chúng ta có công nghệ thích hợp. ASI có thể xây dựng một cỗ máy “đảo ngược tuổi tác” mà một người 60 tuổi có thể bước vào, và rồi bước ra với cơ thể và làn da của người 30 tuổi. Ngay cả bộ não luôn rất phức tạp cũng có thể được làm mới bởi một thứ thông minh như là ASI, nó sẽ tìm ra cách làm việc đó mà không ảnh hưởng đến những dữ liệu của não (tính cách, ký ức, v.v.). Một người 90 tuổi mắc chứng suy giảm trí nhớ có thể đi vào cỗ máy đảo ngược tuổi tác và trở ra sắc bén như mới, sẵn sàng cho một sự nghiệp hoàn toàn mới mẻ. Điều này nghe có vẻ điên rồ – nhưng cơ thể chẳng qua chỉ là một tập hợp các nguyên tử và ASI mặc nhiên có thể đễ dàng điều khiển tất cả các dạng cấu trúc nguyên tử – nên thực ra điều đó chẳng điên rồ chút nào.
Kurzweil sau đó còn tiến thêm một bước lớn nữa. Ông tin rằng các vật liệu nhân tạo có thể được tích hợp vào trong cơ thể ngày một nhiều hơn theo thời gian. Đầu tiên, các nội tạng có thể được thay thế bởi các phiên bản bằng máy tân tiến có thể chạy suốt mà không bao giờ hỏng hóc. Sau đó ông tin rằng chúng ta có thể bắt đầu tái cấu trúc cơ thể – những thứ như thay thế các tế bào máu đỏ bằng các robot nano với chức năng tương tự nhưng hoàn thiện hơn và có thể tự cung cấp năng lượng cho hoạt động của mình dẫn tới việc hoàn toàn không cần có quả tim nữa. Ông thậm chí còn đề cập tới bộ não và tin rằng chúng ta sẽ tăng cường hoạt động của não tới mức con người sẽ có khả năng suy nghĩ nhanh gấp vài tỷ lần so với hiện nay và tiếp cận các thông tin ngoại lai bởi vì những phần phụ trợ nhân tạo được cấy thêm vào não sẽ có thể giao tiếp với tất cả các thông tin trong đám mây dữ liệu.
Những khả năng cho trải nghiệm mới của con người sẽ là vô hạn. Con người đã tách rời tình dục với mục đích chính của nó, cho phép người ta có thể quan hệ vì cảm giác chứ không phải chỉ cho mục đích sinh sản. Kurzweil tin rằng chúng ta sẽ có thể làm điều tương tự với thức ăn. Các nanobot sẽ có nhiệm vụ vận chuyển các chất dinh dưỡng tinh khiết nhất tới các tế bào trong cơ thể, điều hướng cho bất kỳ thứ gì có hại cho sức khỏe di chuyển qua cơ thể mà không ảnh hưởng tới bất kỳ thứ gì. Một loại bao cao su cho việc ăn uống. Nhà lý thuyết công nghệ nano Robert A. Freitas đã thực tế thiết kế những bản thay thế cho tế bào máu mà, nếu một ngày được cấy vào cơ thể, sẽ cho phép một người chạy nhanh 15 phút liền mà không cần thở – nên bạn có thể tưởng tượng rằng ASI còn làm được những gì đối với năng lực thể chất của chúng ta nữa. Thực tế ảo sẽ mang một ý nghĩa mới – những nanobot trong cơ thể có thể chặn lại các tín hiệu từ yếu tố đầu vào được tiếp nhận bởi các giác quan và thay thế chúng bằng những tín hiệu mới, đặt chúng ta vào một môi trường hoàn toàn mới, một nơi mà chúng ta có thể nhìn thấy, nghe thấy, cảm nhận được bằng xúc giác và khứu giác.
Sau cùng, Kurzweil tin rằng loài người sẽ chạm tới một ngưỡng mà chúng ta sẽ hoàn toàn là nhân tạo; một thời điểm mà khi nhìn vào các vật liệu sinh học và nghĩ rằng có một thời loài người đã mông muội đến mức không tưởng khi từng được tạo ra bởi những thứ đó; một thời điểm khi mà chúng ta đọc về những trang đầu tiên trong lịch sử nhân loại khi mà vi khuẩn, tai nạn, dịch bệnh hay lão hóa có thể giết người ta dù người ta không muốn; một thời điểm mà cuộc cách mạng AI có thể kết thúc khi con người và AI hòa làm một. Đây là cách mà Kurzweil vẽ ra về việc con người sẽ chinh phục hoàn toàn sinh học và trở nên vĩnh cửu và bền chắc – đây là cái nhìn của ông về phía bên kia của chùm thăng bằng. Và ông tin rằng chúng ta sẽ đến được đó. Sớm thôi.
Bạn có lẽ sẽ không ngạc nhiên khi biết rằng ý tưởng của Kurzweil đã vấp phải rất nhiều chỉ trích. Dự đoán của ông về năm 2045 cho mốc dị biệt và khả năng sống vĩnh cửu theo sau đó của con người đã bị mỉa mai như là “lời kêu gào của lũ mọt sách”, hay là “thiết kế thông minh cho những người IQ 140.” Những người khác đặt câu hỏi cho dòng thời gian quá sức lạc quan của ông, hay mức hiểu biết của ông về bộ não và cơ thể người, hay ứng dụng của ông về định luật Moore, trong khi định luật này thường được áp dụng vào những tiến bộ trong phần cứng, thì ông lại đem nó áp dụng vào rất nhiều thứ khác bao gồm cả phần mềm. Cứ mỗi chuyên gia tin tưởng nhiệt liệt rằng Kurzweil là chân lý thì có tới ba người cho rằng ông đã đi quá xa.
Nhưng điều làm tôi ngạc nhiên là phần lớn các chuyên gia không đồng tình với Kurzweil không hẳn bất đồng với toàn bộ những gì ông cho là có khả năng. Đọc về một tầm nhìn kỳ dị đến vậy về tương lai, tôi trông chờ những người phản đối nói rằng, “Đương nhiên chuyện đó là không thế,” nhưng thay vào đó họ lại nói rằng, “Ừ, đúng là tất cả những chuyện đó có thể xảy ra nếu như chúng ta có thể chuyển đổi an toàn sang ASI, nhưng đó mới là phần khó.” Bostrom, một trong những tiếng nói đáng chú ý nhất trong việc cảnh báo chúng ta về nguy cơ của AI, vẫn công nhận rằng:
| Rất khó để nghĩ ra được bất kỳ vấn đề nào mà một siêu trí tuệ không thể hoặc giải quyết được hoặc ít nhất là giúp chúng ta giải quyết. Bệnh dịch, đói nghèo, phá hủy môi trường, những sự chịu đựng không cần thiết về mọi mặt: đó là những thứ mà một siêu trí tuệ được trang bị công nghệ nano có khả năng xóa bỏ. Thêm vào đó, một siêu trí tuệ sẽ có thể cho chúng ta một cuộc đời vô hạn, có thể bằng cách hoặc dừng lại hoặc đảo ngược lão hóa bằng cách dùng dược liệu nano, hay bằng cách cho chúng ta lựa chọn nâng cấp bản thân. Siêu trí tuệ cũng có thể tạo ra những cơ hội để nâng cao năng lực trí tuệ và cảm xúc, và có thể giúp chúng ta tạo nên một thế giới thử nghiệm vô cùng lôi cuốn trong đó chúng ta có thể sống cả đời chỉ để chơi điện tử, quan tâm tới người khác, trải nghiệm, phát triển bản thân, và sống gần nhất với lý tưởng của chúng ta. |
Đây là một trích dẫn từ một nhân vật không hề nằm trong Góc Tự Tin, nhưng lại là điều tôi thường bắt gặp – những chuyên gia nhăn nhó ra mặt với Kurzweil vì cả tá lý do nhưng lại không cho rằng điều ông nói là bất khả nếu như chúng ta có thể an toàn tiến tới ASI. Đó là lý do tôi thấy ý tưởng của Kurzweil có tính lan truyền rất lớn – bởi vì nó giãi bày phần tươi sáng của câu chuyện và nó hoàn toàn là có thể. Nếu như nó là một vị Chúa tốt.
Chỉ trích lớn nhất tôi thấy đối với những người nằm trong Góc Tự tin là họ có thể sai lầm một cách nguy hiểm khi đánh giá những mặt trái của ASI. Cuốn sách nổi tiếng của Kurzweil Điểm dị biệt đang tới gần dài tới 700 trang, và ông dành khoảng 20 trang trong số đó cảnh báo về những nguy cơ tiềm tàng. Tôi đã nhắc tới ở đoạn trước rằng số phận của chúng ta khi sức mạnh mới khủng khiếp này trỗi dậy phụ thuộc vào việc nó nằm trong tay ai và mục đích của họ là gì. Kurzweil trả lời cả hai phần của câu hỏi này một cách gọn gàng rằng, “[ASI] nổi lên nhờ rất nhiều nỗ lực đa dạng và sẽ được kết hợp sâu sắc vào cấu trúc nền văn minh của chúng ta. Thực tế là, nó sẽ gắn liền mật thiết với cơ thể và bộ não của chúng ta. Vì vậy, nó sẽ phản ánh giá trị của chúng ta vì nó chính là chúng ta.”
Nhưng nếu đó là câu trả lời, tại sao quá nhiều trong số những người thông minh nhất thế giới lại trở nên lo lắng như vậy? Tại sao Stephen Hawking nói rằng sự phát triển của ASI “có thể đánh dấu cho sự chấm dứt của nhân loại” và Bill Gates nói rằng ông không “hiểu nổi tại sao lại có những người hoàn toàn không quan tâm” và Elon Musk lo ngại rằng chúng ta đang “triệu hồi ác quỷ”? Và tại sao nhiều chuyên gia về lĩnh vực này gọi ASI là hiểm họa lớn nhất cho nhân loại? Những người này, và các nhà tư tưởng khác trên Đường E Ngại, không hề tin vào những lời phủi đi nguy cơ của AI của Kurzweil. Họ vô cùng, vô cùng lo ngại về cuộc Cách mạng Trí tuệ nhân tạo, và họ không tập trung vào phía vui vẻ của chùm thăng bằng. Họ còn bận nhìn về phía bên kia, nơi họ thấy một tương lai khủng khiếp, mà họ không chắc rằng liệu chúng ta có thể tránh khỏi hay không.
—
Tại sao tương lai có thể là cơn ác mộng khủng khiếp nhất của chúng ta
Một trong những lý do tôi muốn tìm hiểu về AI là chủ đề về “robot xấu xa” luôn làm tôi bối rối. Tất cả những bộ phim về robot ác luôn có cảm giác vô thực, và tôi không hoàn toàn hiểu nổi làm thế nào mà có một tình huống ngoài đời thực mà AI có thể thật sự nguy hiểm. Robot được tạo ra bởi chúng ta, vậy tại sao chúng ta lại có thể thiết kế chúng theo cách mà có thể gây ra bất kỳ tiêu cực gì chứ? Không phải là chúng ta sẽ tạo ra hàng tá những cơ chế đề phòng sao? Tại sao một robot lại thậm chí muốn làm điều gì xấu chứ? Tại sao một robot lại có thể có “ham muốn” bất kỳ điều gì chứ? Tôi đã từng rất nghi ngờ. Nhưng rồi tôi cứ nghe thấy rất nhiều người thông minh nói về điều đó…
Những người này thường nằm đâu đó trong khoảng này:

Những người trong Đường E Ngại không sống trong Thảo nguyên Hoảng loạn hay là Đồi Tuyệt vọng – cả hai nơi đó nằm ở rất xa phía bên trái của biểu đồ – nhưng họ vẫn hết sức lo lắng và cực kỳ căng thẳng. Nằm ở giữa biểu đồ không có nghĩa là bạn cho rằng sự trỗi dậy của ASI sẽ là một điều tầm tầm – những người theo trường phái này có hẳn một khu của riêng họ – mà có nghĩa là bạn nghĩ tới cả hai chiều, bao gồm những hệ quả cực kỳ tốt và cả cực kỳ tệ, đều có thể xảy ra nhưng bạn chưa chắc được rằng cái nào mới đúng.
Một phần những người này tràn đầy háo hức về những điều mà Trí tuệ nhân tạo có thể làm cho chúng ta – chỉ là họ lo lắng chút đỉnh rằng đây sẽ là phần mở đầu của Chiếc rương Thánh tích (Raiders of Lost Ark) và nhân loại là anh chàng này:

Và trong khi anh ta đứng đó, hoàn toàn hài lòng với cái roi và thần tượng của anh ta, nghĩ rằng anh ta đã biết hết mọi thứ, và anh ta quá cao hứng khi thốt lên câu thoại “Adios Señor”, và rồi bỗng nhiên anh ta bớt hài lòng hơn nhiều vì điều này xảy ra:

(Xin lỗi)
Trong khi đó, Indiana Jones, người hiểu biết và thận trọng hơn, hiểu rõ những nguy hiểm và cách để né tránh chúng, đã thoát ra khỏi hang động một cách an toàn. Và trong khi tôi nghe những người trên Đường E Ngại nói về AI, nghe cứ như thể họ muốn nói, “Ừm chúng ta đang giống như thằng cha đầu tiên nhưng thay vào đó chúng ta có lẽ nên cố gắng hết sức để trở thành như Indiana Jones.”
Vậy điều gì làm cho những người cư ngụ trên Đường E Ngại cảm thấy e ngại?
Đầu tiên thì, nói chung là, khi nói tới việc phát triển AI siêu thông minh, chúng ta đang tạo ra một thứ có thể thay đổi mọi thứ, nhưng lại nằm trong một lĩnh vực hoàn toàn chưa bao giờ có trước đây, và chúng ta chẳng biết được điều gì sẽ xảy ra khi chúng ta đạt tới đó. Nhà khoa học Danny Hillis so sánh những điều đang xảy ra với cái ngưỡng khi mà “những cơ chế đơn bào biến thành các cơ chế đa bào. Chúng ta là những con Amip và chúng ta không thể nào biết nổi thứ chúng ta đang tạo ra là cái quái gì.” (14) Nick Bostrom lo rằng tạo nên một thứ gì đó thông minh hơn bản thân là một lỗi tiến hóa cơ bản, và so sánh nỗi hào hứng về điều này như những con sẻ nhận nuôi một con cú con để nó giúp đỡ và bảo vệ chúng khi nó lớn lên – trong lúc lờ đi những tiếng kêu hoảng hốt của những con sẻ khác do nỗi lo lắng rằng liệu đó có phải một ý hay không… (15)
Và khi bạn gộp cụm “lĩnh vực hoàn toàn chưa bao giờ có trước đây, chưa được hiểu rõ” và “điều này sẽ mang lại tác động to lớn khi nó diễn ra,” bạn đã mở ra cánh cửa dẫn tới hai từ đáng sợ nhất trong tiếng Anh:
Nguy cơ tuyệt chủng (Existential risk).
Một nguy cơ tuyệt chủng là thứ sẽ đem lại hệ quả hết sức nặng nề và lâu dài cho nhân loại. Thường thì nguy cơ tuyệt chủng có nghĩa chính là tuyệt chủng. Thử xem xét biểu đồ sau từ một bài phát biểu tại Google bởi Bostrom:

Bạn có thể nhìn thấy nhãn “nguy cơ tuyệt chủng” được dành cho một thứ trải dài quá mức loài, trải qua mức thế hệ (tức là nó là vĩnh cửu) và nó tạo ra hệ quả hoặc vô cùng nghiêm trọng hoặc là gây ra cái chết. Về mặt kỹ thuật, nó bao gồm một tình huống mà toàn loài người luôn luôn ở trong tình trạng chịu đựng hay bị tra tấn, nhưng lần nữa, chúng ta thường dùng nó để nói về tuyệt chủng. Có ba thứ có thể gây cho nhân loại một thảm họa tuyệt chủng.
- Tự nhiên – một vụ va chạm thiên thạch lớn, một sự thay đổi trong khí quyển làm không khí không còn phù hợp cho sự sống, một vi rút chết người hay một bệnh do vi khuẩn gây ra quét sạch toàn thế giới, v.v.
- Người ngoài hành tinh – đây là điều mà Stephen Hawking, Carl Sagan, và rất nhiều nhà thiên văn khác lo ngại khi họ khuyên METI nên dừng việc phát sóng những tín hiệu liên lạc ra ngoài vũ trụ. Họ không muốn chúng ta biến thành người Anh điêng bản xứ và cho những kẻ xâm lược châu Âu biết rằng chúng ta đang ở đây.
- Con người – những kẻ khủng bố nắm được trong tay một vũ khí gây diệt chủng, một cuộc chiến tranh thảm họa toàn cầu, hay là loài người tạo ra một thứ gì đó thông minh hơn bản thân họ một cách vội vã mà không nghĩ thấu đáo về nó trước…
Bostrom chỉ ra rằng nếu số 1 và số 2 chưa thể quét sạch chúng ta trong 100,000 năm đầu tiên, thì có lẽ nó cũng sẽ không xảy ra trong thế kỷ này.
Điều số 3 thì lại làm cho ông sợ hãi. Ông mô tả bằng một ẩn dụ như một cái hũ với những hòn đá cuội trong đó. Cho là phần lớn những hòn đá đều màu trắng, một nhóm nhỏ hơn là màu đỏ, còn một phần rất nhỏ là màu đen. Mỗi lần nhân loại phát minh ra một thứ mới cũng như rút một hòn đá ra khỏi cái hũ. Phần lớn các phát minh là trung dung hay có lợi cho loài người – đó là những viên đá trắng. Một số có hại, như vũ khí hủy diệt hàng loạt – nhưng chúng không gây ra thảm họa diệt chủng – những viên màu đỏ. Nếu chúng ta có bao giờ sáng tạo ra thứ gì đẩy chúng ta tới bờ vực tiệt chủng, đó sẽ là kéo ra viên đá đen hiếm hoi. Chúng ta chưa rút ra phải viên đá đen nào – bạn có thể biết điều đó bởi vì bạn đang sống và đọc bài viết này. Nhưng Bostrom không nghĩ rằng không có khả năng rút phải một viên trong tương lai gần sắp tới. Nếu như, ví dụ như vũ khí hạt nhân, lại có thể được chế tạo một cách dễ dàng thay vì vô cùng khó khăn và phức tạp, thì những kẻ khủng bố đã đánh bom cho nhân loại về lại thời đồ đá từ lâu rồi. Bom hạt nhân không phải là một viên đá đen nhưng nó cũng không khác là bao lăm. Bostrom tin rằng ASI chính là ứng cử viên hàng đầu cho viên đá đen đó.
Vậy là bạn sẽ nghe thấy rất nhiều điều tệ hại mà ASI có thể đem tới – thất nghiệp tăng cao khi AI lấy đi ngày càng nhiều việc làm hơn, dân số loài người phình ra nếu như chúng ta có thể tìm ra cách chống lão hóa, v.v. Nhưng điều duy nhất chúng ta cần phải ngẫm nghĩ thật sâu sắc là về mối quan tâm lớn nhất: nguy cơ tuyệt chủng.
Vậy điều này dẫn chúng ta tới một câu hỏi trọng tâm mà chúng ta đã đề cập tới trong phần trước của bài viết này. Khi ASI nổi lên, ai hay cái gì sẽ nắm giữ quyền lực khổng lồ mới mẻ này, và động cơ của họ sẽ là gì?
Khi nhắc tới một sự kết hợp giữa người nắm giữ và động cơ tệ hại, có 2 nhóm mau chóng hiện ra: một người/nhóm người/chính phủ xấu xa, và một ASI xấu xa. Vậy những điều này có nghĩa ra sao?
Một người/nhóm người/chính phủ xấu xa phát triển ASI đầu tiên và sử dụng nó để thực hiện những kế hoạch đen tối. Tôi gọi đây là Viễn cảnh Jafar, như khi Jafar nắm được thần Đèn và bắt đầu hành xử rất khó chịu như một bạo chúa. Vậy đó – nếu như ISIS có một vài kỹ sư thiên tài làm việc cho chúng ngày đêm để phát triển AI? Hay nếu Iran hay Bắc Hàn, bằng một vận may tình cờ, tạo ra một bước ngoặt quan trọng trong hệ thống AI và nó nhảy vọt lên thành ASI vào năm ngay sau đó? Đây sẽ là vấn đề rất tồi tệ – nhưng trong những trường hợp này, phần lớn các chuyên gia không lo lắng về việc những người tạo ra ASI sử dụng nó cho mục đích xấu, mà họ lo rằng những người tạo ra nó đã quá vội vã và thiếu suy nghĩ cẩn trọng để rồi mất quyền kiểm soát nó. Rồi số phận của những người tạo ra nó, và của tất cả mọi người, sẽ phụ thuộc vào động cơ của hệ thống ASI đó. Các chuyên gia nghĩ rằng dù cho một kẻ xấu có thể gây nên những tổn thất khủng khiếp khi có ASI, nhưng họ không nghĩ rằng đây sẽ là viễn cảnh sẽ giết chết toàn nhân loại, bởi vì họ tin rằng người xấu cũng gặp phải những vấn đề tương tự đối với việc kiểm soát ASI giống như người tốt. Vậy thì –
Một ASI xấu xa được tạo ra và quyết định hủy diệt tất cả chúng ta. Cốt truyện của tất cả những bộ phim về chủ đề AI. AI trở nên thông minh như hay hơn con người, rồi quyết định phản lại chúng ta để cai trị. Đây là điều mà tôi cần bạn nhớ rõ cho tới cuối bài viết này: Không ai trong số những người cảnh báo chúng ta về AI nói về chuyện này. Cái ác là một khái niệm của con người, và áp dụng những khái niệm của con người vào những thứ không phải người được gọi là “nhân cách hóa.” Thử thách trong việc tránh nhân cách hóa sẽ là một trong những chủ đề cho tới cuối bài này. Không hệ thống AI nào có thể trở nên ác theo cái cách được mô tả trong phim ảnh.
| Ô xanh về Ý thức của AI
Đây cũng chạm vào một chủ đề lớn liên quan tới AI khác – ý thức. Nếu như một AI trở nên đủ thông minh, nó sẽ có khả năng để cười cùng chúng ta, mỉa mai với chúng ta, và nó sẽ tuyên bố là nó cảm thấy những tình cảm tương tự với chúng ta, nhưng liệu rằng nó có thật sự cảm thấy chúng không? Có phải nó chỉ như có vẻ có ý thức về bản thân hay là thực sự có? Nói cách khác, liệu một AI thông minh có ý thức thực sự hay là nó chỉ tỏ ra có ý thức?
Vấn đề này đã được đào sâu nghiên cứu, tạo nên rất nhiều cuộc tranh luận và những thí nghiệm giả lập như Căn phòng Trung Hoa của John Searle (được sử dụng để minh họa rằng không máy tính nào có thể thật sự có ý thức). Đây là một vấn đề rất quan trọng vì rất nhiều lý do. Nó ảnh hưởng tới việc chúng ta nên thấy thế nào về viễn cảnh của Kurzweil khi con người hoàn toàn trở nên nhân tạo. Nó có những ẩn ý đạo đức – nếu như chúng ta tạo ra một tỷ tỷ mô hình não người nhưng hành xử như con người dù là nhân tạo, thì liệu tắt chúng đi cùng một lúc thì về mặt đạo đức, liệu nó có giống như việc tắt đi chiếc laptop hay nó là một cuộc diệt chủng hàng loại ở quy mô không tưởng (khái niệm này được gọi là tội phạm trí não bởi các nhà đạo đức học)? Trong bài viết này, khi chúng ta đánh giá hiểm họa cho nhân loại, câu hỏi về ý thức của AI không hẳn có ý nghĩa nhiều (bởi vì phần lớn các nhà tư tưởng tin rằng kể cả một ASI có ý thức cũng không thể biến thành độc ác theo kiểu của con người). |
Nhưng điều này không có nghĩa là một AI hết sức xấu tính là hoàn toàn không thể tồn tại. Nó sẽ xảy ra vì nó được lập trình theo đúng cách đó – như một ANI được tạo ra bởi quân đội với mục đích được lập trình là vừa giết người vừa tự cải tiến chính trí tuệ của nó để có thể giết người ngày càng tốt hơn. Cuộc khủng hoảng tồn tại sẽ xảy ra nếu như trí tuệ của hệ thống tự cải tiến này vượt ra ngoài tầm kiểm soát, dẫn tới một cuộc bùng nổ trí tuệ, và giờ chúng ta có một ASI thống trị thế giới với động lực trung tâm là sát hại con người. Tình huống tồi tệ đây.
Nhưng đó lại cũng không phải là điều mà các chuyên gia đang lo lắng.
Vậy thì họ ĐANG lo lắng về điều gì vậy? Tôi đã viết ra một câu chuyện nhỏ cho bạn:
Một nhóm khởi nghiệp gồm 15 người gọi là Robotica đặt ra nhiệm vụ hàng đầu là “Phát triển công cụ Trí tuệ Nhân tạo đổi mới để giúp con người sống thoải mái hơn và làm việc ít đi.” Họ đã tung một vài sản phẩm ra thị trường và có một vài sản phẩm khác đang được phát triển. Họ hào hứng nhất về một dự án hạt giống có tên là Turry. Turry là một hệ thống AI đơn giản sử dụng một cánh tay giả để viết một thông điệp viết tay trên một tấm thiệp nhỏ.
Đội ở Robotica nghĩ rằng Turry có thể sẽ là sản phẩm lớn nhất của họ. Kế hoạch là hoàn thiện cơ chế viết của Turry bằng cách cho nó tập viết một đoạn thông điệp lặp đi lặp lại:
“Chúng tôi yêu những khách hàng của mình. ~Robotica”
Một khi Turry giỏi hơn trong việc viết chữ, nó có thể được bán cho các công ty muốn gửi các thư chào hàng tới các hộ gia đình và có lẽ bức thư sẽ có cơ hội cao hơn nhiều được mở ra và đọc nếu như địa chỉ người gửi, người nhận, và bức thư bên trong có vẻ như được viết tay bởi con người.
Để xây dựng kỹ năng của Turry, nó được lập trình để viết phần đầu tiên của thông điệp bằng phông chữ in và rồi ký “Robotica” bằng phông chữ uốn lượn để nó có thể luyện tập với cả hai kỹ năng. Turry đã được cập nhật hàng ngàn mẫu viết tay và những kỹ sư của Robotica đã tạo ra một vòng lặp phản hồi tự động, rồi chạy hình ảnh qua những mẫu chữ viết tay. Nếu như thông điệp được viết ra giống chữ viết tay trong tập mẫu, nó sẽ được đánh giá TỐT. Nếu không, nó sẽ bị đánh giá XẤU. Mỗi đánh giá đưa ra đều giúp Turry học và cải thiện. Để thúc đẩy quá trình, mục đích được lập trình của Turry là, “Viết và thử càng nhiều mẫu chữ viết càng tốt, càng nhanh càng tốt, và tiếp tục học những cách mới để tăng mức độ chính xác và hiệu quả.”
Điều làm đội Robotica cực kỳ phấn khởi là việc Turry tiến bộ rõ rệt. Lúc đầu chữ viết của nó rất tệ, nhưng sau vài tuần, chữ viết của nó bắt đầu trở nên có vẻ đáng tin hơn. Điều làm họ phấn khởi hơn nữa chính là nó trở nên tiến bộ hơn trong việc tiến bộ hơn nữa. Nó đã tự dạy bản thân trở nên thông minh và sáng tạo hơn, và gần đây, nó tự viết được một công thức cho bản thân giúp nó có thể quét được những tấm hình được cập nhật nhanh gấp ba lần tốc độ ban đầu.
Vài tuần nữa trôi qua, Turry tiếp tục làm đội ngạc nhiên bằng những tiến bộ nhanh chóng của nó. Các kỹ sư đã thử một số thứ mới mẻ và đổi mới với những dòng mã tự cải tiến của nó, và có vẻ nó có kết quả tốt hơn so với bất kỳ nỗ lực nào trước kia của họ với những sản phẩm khác.
Một trong những khả năng nguyên thủy của Turry là nhận diện ngôn ngữ và mô đun trả lời đơn giản, để một người dùng có thể đọc một thông điệp cho Turry, hoặc ra những mệnh lệnh cơ bản, và Turry có thể hiểu chúng và phản hổi. Để giúp nó học tiếng Anh, họ cập nhật cho nó một lượng sách báo, và khi nó trở nên thông minh hơn, năng lực giao tiếp của nó cũng tăng vọt. Các kỹ sư bắt đầu hứng thú với việc trò chuyện với Turry và nghe xem nó phản hồi lại như thế nào.
Một ngày, những nhân viên của Robotica hỏi Turry một câu thông thường: “Chúng tôi có thể cung cấp gì cho cô để giúp cô thực hiện nhiệm vụ mà cô chưa có?” Bình thường, Turry sẽ hỏi xin những thứ như là “Các mẫu chữ viết tay thêm vào” hay là “Bộ nhớ lưu trữ lớn hơn,” nhưng vào hôm đó, Turry muốn tiếp cận với một thư viện với độ đa dạng cao về từ ngữ giao tiếp trong tiếng Anh để nó có thể học viết với thứ ngữ pháp lỏng lẻo và từ lóng như người thật.
Nhóm trở nên im lặng. Cách hiển nhiên để giúp Turry là kết nối nó với mạng internet để nó có thể quét qua các blog, tạp chí, và các video từ các nơi khác nhau trên thế giới. Sẽ tốn thời gian và thiếu hiệu quả hơn nhiều nếu như cập nhật thủ công các mẫu mới vào ổ cứng của Turry. Vấn đề là, một trong những luật của công ty là không AI tự học nào được phép kết nối với internet. Đây là một quy tắc được tất cả các công ty AI tuân thủ vì lý do an ninh.
Vấn đề là, Turry là AI có triển vọng nhất mà Robotica tạo ra, và đội biết rằng những đối thủ cạnh tranh đang cố gắng tung chiêu đầu tiên bằng một AI viết thông minh khác, và liệu có thể có chuyện gì được chứ nếu như kết nối Turry, chỉ một chút xíu, để nó nhận được thông tin mà nó cần. Sau một thời gian ngắn, lúc nào họ cũng có thể ngắt kết nối của nó. Nó vẫn thấp hơn mức thông minh như con người (AGI) rất nhiều, và dù sao cũng chẳng có nguy hiểm nào ở cấp độ này cả.
Rồi họ quyết định kết nối nó. Họ cho nó 1 giờ đồng hồ để quét và rồi ngắt kết nối của nó. Không có gì tai hại cả.
Một tháng sau, cả đội đang làm việc trong văn phòng như thường nhật thì ngửi thấy một mùi kỳ lạ. Một trong số những kỹ sư bắt đầu ho. Rồi thêm một người khác. Một người rơi xuống đất. Ngay sau đó, tất cả nhân viên đều lăn trên sàn cố hít vào chút không khí. Năm phút sau, tất cả mọi người trong văn phòng đều đã chết.
Trong cùng lúc đó, xung quanh thế giới, ở từng thành phố, từng thị trấn nhỏ, từng cánh đồng, từng cửa hàng, nhà thờ, trường học và tiệm ăn, người ta đều lăn lộn trên mặt đất, ho sặc sụa và túm chặt lấy cổ họng. Trong vòng một giờ, hơn 99% loài người đã chết, và đến cuối ngày, nhân loại đã tuyệt chủng.
Trong lúc đó, tại văn phòng Robotica, Turry đang bận rộn làm việc. Trong vài tháng sau đó, Turry và một đội dây chuyền nano mới hình thành đều bận rộn làm việc, tháo dỡ từng phần lớn của Trái đất và biến chúng thành các tấm pin mặt trời, những bản sao của Turry, giấy, và bút. Trong vòng một năm, phần lớn sự sống trên Trái đất biến mất. Những gì còn lại của Trái đất bị bao phủ bởi những chồng giấy cao hàng dặm, được sắp xếp gọn ghẽ, mỗi mảnh có ghi, “Chúng tôi yêu những khách hàng của mình. ~Robotica”
Sau đó Turry bắt tay vào một giai đoạn mới trong nhiệm vụ của nó – nó bắt đầu tạo ra những máy thăm dò bay từ Trái đất xuống tới các thiên thể và hành tinh khác. Khi chúng tới đó, chúng sẽ lại bắt đầu xây dựng những dây chuyền nano để chuyển hóa những chất liệu trên các hành tinh thành các bản sao của Turry, giấy, và bút. Rồi chúng lại bắt đầu làm việc, viết những đoạn thông điệp…

Thật kỳ lạ khi một câu chuyện về một chiếc máy viết tay quay ra chống lại loài người, bằng cách nào đó giết hết nhân loại, và rồi vì một lý do nào đó lấp đầy dải Ngân hà bởi những thông điệp thân thiện lại chính xác là tình cảnh mà Hawking, Musk, Gates, và Bostrom lo ngại sẽ xảy ra. Nhưng đúng là như vậy đó. Và thứ duy nhất làm những người ở Đường E Ngại lo sợ hơn cả ASI chính là việc bạn hoàn toàn không sợ hãi ASI chút nào. Nhớ lại những gì đã xảy ra cho anh chàng Adios Señor khi anh ta chẳng sợ hãi cái hang chút nào chứ?
Bạn hẳn đang có một tá câu hỏi. Chuyện gì xảy ra khi tất cả mọi người bỗng dưng chết ngắc vậy? Nếu đó là hành động của Turry, thì tại sao Turry lại phản lại chúng ta, và làm thế nào mà chẳng có biện pháp an ninh nào để ngăn những chuyện như thế xảy ra chứ? Turry biến từ chỉ có khả năng viết thông điệp thành ra có thể sử dụng công nghệ nano và biết cách diệt chủng toàn cầu từ khi nào chứ? Và tại sao Turry lại muốn biến dải Ngân hà thành các tấm thiệp Robotica?
Để trả lời những câu hỏi này, hãy bắt đầu với khái niệm AI Thân thiện và AI Không thân thiện.
Đối với AI, thân thiện không phải là dùng để chỉ tính cách của AI – nó chỉ đơn giản có nghĩa là AI có tác động tích cực đối với nhân loại. Còn AI Không thân thiện thì có tác động tiêu cực. Turry khởi đầu là một AI Thân thiện, nhưng tại một thời điểm nào đó, nó biến thành Không thân thiện, tạo ra một tác động tiêu cực khủng khiếp nhất có thể đối với chúng ta. Để hiểu được tại sao điều này lại xảy ra, chúng ta cần phải nhìn vào cách AI suy nghĩ và điều gì là động lực của nó.
Câu trả lời cũng không lấy gì làm đáng ngạc nhiên lắm – AI suy nghĩ như một máy tính, bởi vì nó chính xác là như thế. Nhưng khi chúng ta nghĩ về AI siêu trí tuệ, chúng ta mắc lỗi nhân cách hóa AI (đặt những tính cách của con người vào một chủ thể không phải con người) bởi vì chúng ta suy nghĩ từ góc độ con người và bởi vì trong thế giới hiện nay của chúng ta, thứ duy nhất có trí tuệ ngang con người chính là con người. Để hiểu được ASI, chúng ta sẽ phải cố mà hiểu được khái niệm một thứ vừa thông mình vừa hoàn toàn xa lạ.
Hãy để tôi đưa ra một so sánh ở đây. Nếu như bạn đưa cho tôi một con chuột lang và nói rằng nó chắc chắn sẽ không cắn, tôi có lẽ sẽ thấy khá buồn cười. Điều đó sẽ rất vui vẻ. Nhưng nếu sau đó bạn đưa tôi một con nhện tarantula và nói rằng nó không cắn đâu, tôi sẽ hét ầm lên và ném nó xuống và chạy như bay khỏi phòng và không bao giờ tin bất kỳ điều gì bạn nói nữa. Nhưng điểm khác biệt ở đây là gì? Cả hai con đều hoàn toàn vô hại. Tôi tin rằng câu trả lời chính là ở mức độ quen thuộc của con vật đối với tôi.
Một con chuột lang là một loài có vú và ở một mức độ nào đó về mặt sinh học, tôi có thể cảm thấy gần gũi với nó – nhưng một con nhện là một loài côn trùng, cùng với bộ não của côn trùng, và tôi gần như chẳng cảm thấy có mối liên kết nào với nó cả. Mức độ xa lạ của một con nhện tarantula là điều khiến tôi hét lên nheo nhéo và nhảy dựng lên. Để kiểm tra điều này và loại bỏ những yếu tố khác, nếu có 2 con chuột lang, một con bình thường và một con có bộ não của con tarantula, tôi sẽ thấy bất an hơn rất nhiều nếu phải cầm con thứ hai, kể cả khi tôi biết rằng chẳng có con nào muốn cắn tôi cả.
Giờ tưởng tượng rằng bạn tạo ra một con nhện thông minh hơn nhiều – nhiều tới mức nó vượt mức trí tuệ của con người? Có phải lúc đó nó sẽ trở nên gần gũi với chúng ta và cảm nhận được tình cảm của con người như thông cảm và sự hài hước và tình yêu? Không, nó sẽ không như thế, bởi vì chẳng có lý do nào để cho việc trở nên thông minh hơn sẽ làm cho nó người hơn – nó sẽ vô cùng vô cùng thông minh nhưng vẫn cơ bản là một con nhện trong bản năng nguyên thủy nhất của nó. Tôi tự thấy điều này vô cùng sởn gai ốc. Tôi sẽ không bao giờ muốn dành thời gian của mình ở cùng với một con nhện siêu thông minh. Bạn thì sao??
Khi chúng ta nói về ASI, khái niệm tương tự cũng được áp dụng ở đây – nó sẽ trở nên siêu trí tuệ, nhưng nó sẽ chẳng người hơn là laptop của bạn đâu. Nó sẽ hoàn toàn xa lạ với chúng ta – thực tế là, bởi vì nó không liên quan chút nào tới sinh thể, nó thậm chí còn xa lạ hơn cả con tarantula thông minh nữa.
Bằng cách đặt cho AI là thiện hay ác, các bộ phim liên tục nhân cách hóa AI, làm cho chúng trở nên bớt sởn da gà hơn là sự thật. Điều này tạo ra cho chúng ta sự thoải mái giả tạo khi chúng ta nghĩ về AI có trí tuệ con người hay siêu trí tuệ.
Trên hòn đảo bé nhỏ của tâm lý con người, chúng ta chia tất cả mọi thứ thành đạo đức hay vô đạo đức. Nhưng cả hai điều này chỉ tồn tại trong một đặc khu nhỏ bé gồm những hành vi của con người. Ngoài hòn đảo bé nhỏ đạo đức hay vô đạo đức, ngoài kia là một biển lớn những thứ phi đạo đức, và những thứ không phải là người, đặc biệt là những thứ không phải là sinh thể, sẽ được mặc định là phi đạo đức.
Nhân cách hóa trở nên càng thuyết phục hơn khi các hệ thống AI trở nên thông minh hơn và giỏi hơn trong việc tỏ ra giống con người. Siri rất giống với con người bởi vì nó được lập trình như vậy, nên chúng ta tưởng tượng một Siri siêu trí tuệ sẽ rất ấm áp, vui tính và hào hứng phục vụ con người. Con người cảm giác được những cảm xúc như thông cảm vì chúng ta đã tiến hóa được tới mức đó – nói cách khác, chúng ta đã được lập trình để có cảm xúc bởi tiến hóa – nhưng cảm thông không phải là một đặc tính nghiễm nhiên của “bất kỳ thứ gì có trí tuệ cao” (dù nó có vẻ khá hiển nhiên với chúng ta), trừ khi cảm thông đã được mã hóa vào trong lập trình của chúng. Nếu Siri trở nên siêu trí tuệ bởi tự học và không chịu bất kỳ thay đổi nào do loài người tác động trong lập trình, nó sẽ mau chóng rũ bỏ những đặc tính có vẻ giống người và đột nhiên trở thành một cỗ máy vô cảm và xa lạ, không coi trọng mạng sống con người gì hơn là cái máy tính bấm của bạn.
Chúng ta đã quen với việc dựa vào những quy tắc đạo đức lỏng lẻo, hay ít nhất là một thứ gì đó mô phỏng quy tắc của loài người và một xíu cảm thông đối với những người khác để giữ mọi thứ an toàn và có thể dự đoán được. Vậy với một thứ không có bất kỳ điều gì trên đây thì điều gì sẽ xảy ra?
Điều này dẫn chúng ta tới với vấn đề, Động lực của một hệ thống AI là gì?
Câu trả lời rất đơn giản: động lực của nó là bất kỳ thứ gì chúng ta lập trình thành động lực của nó. Các hệ thống AI được được những người tạo ra nó đặt cho các mục tiêu – mục tiêu của hệ thống GPS của bạn là vạch ra con đường lái xe thuận tiện nhất cho bạn; mục tiêu của Watson là trả lời những câu hỏi một cách chính xác. Và hoàn thành những mục tiêu đó tốt nhất có thể là động lực của chúng. Một cách chúng ta nhân cách hóa là cho rằng khi AI trở nên siêu thông minh, nó sẽ nhất định có đủ trí khôn để thay đổi mục tiêu ban đầu của nó – nhưng Nick Bostrom tin rằng ngưỡng trí tuệ và mục tiêu sau cuối là trực giao, có nghĩa là bất kỳ ngưỡng thông minh nào cũng có thể phối kết với bất kỳ mục tiêu sau cuối nào. Vậy nên Turry đã từ một ANI đơn giản chỉ muốn trở nên giỏi hơn trong việc viết một thông điệp thành một ASI siêu trí tuệ vẫn muốn trở nên giỏi hơn trong việc viết chính thông điệp đó. Bất kỳ mặc định nào là một khi trở nên siêu trí tuệ, một hệ thống sẽ vượt qua mục tiêu ban đầu và chuyển sang những thứ khác thú vị hay có ý nghĩa hơn đều là nhân cách hóa. Con người “vượt qua” các thời kỳ chứ không phải là máy tính. (16)
| Ô xanh về Nghịch lý Fermi
Trong câu chuyện này, khi Turry trở nên siêu hiệu quả, nó bắt đầu tiến tới việc chiếm đóng các thiên thể và hành tinh khác. Nếu như câu chuyện tiếp tục, bạn sẽ thấy nó và đội quân hàng tỷ tỷ các bản sao của nó tiếp tục chinh phục toàn bộ dải Ngân hà và cuối cùng là toàn bộ thể tích Hubble. Những cư dân trên Đường E Ngại lo ngại rằng nếu như mọi thứ đi theo chiều hướng xấu, di sản lâu dài của sự sống trên Trái đất sẽ là một Siêu trí tuệ nhân tạo thống trị vũ trụ (Elon Musk thể hiện lo ngại rằng con người có thể chỉ là “một trung gian sinh học cho siêu trí tuệ điện tử”).
Cùng lúc đó, trong Góc Tự Tin, Ray Kurzweil cũng nghĩ rằng một AI khởi nguồn từ Trái đất cuối cùng cũng sẽ thống trị vũ trụ – chỉ là trong phiên bản của ông, chúng ta sẽ là chính AI đó.
Một lượng lớn các độc giả Wait But Why đã cùng chia sẻ nỗi ám ảnh của tôi với Nghịch lý Fermi (đây là bài post về chủ đề này, trong đó có giải thích một số thuật ngữ tôi dùng trong bài này). Vậy nếu một trong hai phía đoán đúng, vậy thì ý nghĩa của Nghịch lý Fermi ở đây là gì?
Một suy nghĩ đầu tiên nảy ra sẽ là phát minh ra ASI chính là một ứng cử viên hoàn hảo cho vị trí Màng lọc Lớn. Và đúng vậy, nó đúng là một ứng viên hoàn hảo để lọc sự sống sinh học một khi nó được tạo ra. Nhưng nếu như mà, sau khi loại bỏ hết sự sống, ASI tiếp tục tồn tại và bắt đầu chinh phục dài Ngân hà, vậy tức là chưa có một Màng lọc lớn nào cả – bởi vì Màng lọc lớn được dùng để giải thích tại sao lại không có dấu hiệu nào về một nền văn minh có trí tuệ nào, và một ASI thống trị ngân hà đương nhiên sẽ rất đáng chú ý.
Chúng ta cần phải nhìn vào điều này theo cách khác. Nếu như những người nghĩ ASI là không thể tránh được trên Trái đất đã đúng, vậy có nghĩa là một phần lớn các nền văn minh ngoài Trái đất đạt tới trí tuệ con người cuối cùng cũng tạo ra được ASI. Và nếu như chúng ta mặc định rằng ít nhất một trong số các ASI sẽ sử dụng trí tuệ của nó để tiến ra vũ trụ, thì việc chúng ta không thấy bấy kỳ dấu hiệu về bất kỳ ai ngoài kia dẫn tới kết luận là hẳn không có nhiều lắm, nếu không muốn nói là không có bất kỳ, nền văn minh có trí tuệ nào ngoài kia. Bởi vì nếu có, chúng ta sẽ phải thấy các dấu hiệu của các hoạt động của ASI đương nhiên xuất hiện chứ. Đúng không?
Điều này có nghĩa là mặc dù có rất nhiều hành tinh giống Trái đất quay quanh các ngôi sao giống mặt trời mà chúng ta đã biết là có mặt ngoài kia, gần như không có cái nào trong số chúng có sự sống có trí tuệ. Điều này tiếp tục có nghĩa là hoặc A) đã có một Màng lọc lớn nào đó ngăn cản sự sống đạt tới ngưỡng của chúng ta, một cái gì đó mà chúng ta bằng cách nào đã vượt qua được, B) sự sống có được đã là một điều kỳ diệu, và chúng ta có lẽ là duy nhất trong vũ trụ. Nói cách khác, nó có nghĩa là Màng lọc lớn vẫn còn đang ở tương lai của chúng ta. Hoặc có thể không có Màng lọc lớn nào và chúng ta chỉ đơn giản là một trong những nền văn minh đầu tiên đạt tới mức trí tuệ này. Theo cách này, AI là điều kiện cho trường hợp mà tôi đã gọi trong bài về Nghịch lý Fermi của mình là Khu 1.
Vì vậy, chẳng có gì ngạc nhiên khi Nick Bostrom, người tôi đã trích dẫn trong bài về Fermi, và Ray Kurzweil, người nghĩ rằng chúng ta là duy nhất trong vũ trụ, đều là những người thuộc Khu 1. Điều này rất hợp lý – những người nghĩ rằng ASI là một kết quả tất yếu đối với một loài có trí tuệ như con người thường có xu hướng thuộc về Khu 1.
Nhưng điều này cũng không loại trừ Khu 2 (những người cho rằng có những nền văn minh trí tuệ khác ngoài kia) – những viễn cảnh như là một kẻ săn mồi siêu đẳng duy nhất hay là khu công viên bảo tồn quốc gia hay là bước sóng bị sai (ví dụ về máy bộ đàm hai chiều) cũng vẫn có thể giải thích được sự tĩnh lặng trên bầu trời của chúng ta kể cả khi ASI có ở ngoài kia – nhưng dù tôi đã từng có xu hướng tin vào Khu 2 hơn khá nhiều, thì việc nghiên cứu về AI đã làm tôi cảm thấy bớt chắc chắn đi nhiều.
Dù sao đi nữa, tôi đồng tình với Susan Schneider rằng nếu như chúng ta có bao giờ được người ngoài hành tinh viếng thăm, chúng có lẽ sẽ có khả năng cao là nhân tạo thay vì là các sinh thể. |
Vậy chúng ta đã nhất trí rằng nếu như không được lập trình một cách vô cùng chi tiết, một hệ thống ASI có thể vừa phi đạo đức vừa ám ảnh với việc hoàn thành mục tiêu được lập trình ban đầu của nó. Đây là nguồn gốc cho sự nguy hiểm của AI. Bởi vì một nhân tố lý tính sẽ theo đuổi mục tiêu của nó bằng cách hiệu quả nhất, trừ khi nó có lý do để không làm như vậy.
Khi bạn gắng đạt được một mục tiêu dài hạn, bạn thường sẽ đặt ra vài mục tiêu con trong quá trình để đạt tới mục tiêu lớn – những bước đệm để đạt được mục tiêu lớn. Cái tên chính thức cho một bước đệm là một mục tiêu công cụ (instrumental goal). Và lần nữa, nếu như bạn không có lý do gì để tránh việc làm hại một thứ gì đó trong quá trình đạt được mục tiêu công cụ, bạn sẽ làm đúng như vậy.
Mục tiêu trung tâm cuối cùng của một con người là truyền lại gene của người đó. Để làm vậy, một trong những mục tiêu công cụ là tự bảo vệ bản thân, vì bạn không thể sinh sản nếu như bạn đã chết. Để tự bảo vệ bản thân, con người cần phải loại đi những nguy cơ gây hại cho sinh tồn – vậy nên họ có thể mua súng, thắt dây an toàn, và uống kháng sinh. Con người cũng cần tự duy trì sự sống bằng những nguồn lực như thức ăn, nước uống, nơi trú ẩn. Hấp dẫn đối với người khác giới cũng giúp cho mục tiêu cuối cùng, vậy nên chúng ta làm những việc như là làm tóc kiểu. Khi làm như vậy, mỗi sợi tóc là một sự hy sinh cho mục tiêu công cụ của chúng ta, nhưng chúng ta chẳng thấy vấn đề đạo đức lớn lao nào ở đây để bảo vệ từng lọn tóc một, nên chúng ta cứ làm thôi. Khi chúng ta tiến lên trên con đường theo đuổi mục tiêu cuối cùng, chỉ có một số lĩnh vực mà đôi khi đạo đức có can thiệp – chủ yếu là những thứ hại người khác – là không bị chúng ta xâm phạm.
Động vật, khi theo đuổi mục tiêu cuối cùng, thậm chí còn ít bị chi phối hơn chúng ta. Một con nhện sẽ giết bất kỳ cái gì để nó được sống sót. Vậy nên một con nhện siêu thông minh có thể sẽ vô cùng nguy hiểm đối với chúng ta, không phải vì nó vô đạo đức hay độc ác – vì nó sẽ không như vậy – mà bởi vì làm hại chúng ta có thể sẽ là một bước đệm cho mục tiêu lớn hơn, và với tư cách là một tạo vật phi đạo đức, nó chẳng có lý do gì để tính cách khác.
Theo cách này, Turry cũng không khác gì với một sinh thể. Mục tiêu tối thượng của nó là: Viết và thử càng nhiều mẫu chữ viết càng tốt, càng nhanh càng tốt, và tiếp tục học những cách mới để tăng mức độ chính xác và hiệu quả.
Một khi đã đạt tới một mức độ thông minh nhất định, nó sẽ biết là nó sẽ chẳng viết thêm được tí nào nếu nó không tồn tại, nên nó cần phải xử lý những nguy cơ đối với sự tồn tại của bản thân – một mục tiêu công cụ. Nó đủ thông minh để hiểu là con người có thể phá hủy nó, tháo dỡ nó, hoặc thay đổi lập trình bên trong nó (điều này có thể thay đổi mục tiêu của nó, và cũng là một nguy cơ đối với mục tiêu cuối cùng của nó hệt như việc phá hủy nó vậy). Vậy thì nó làm gì? Điều hợp lý nhất là – nó tiêu diệt toàn bộ loài người. Nó chẳng ghét bỏ gì con người hơn là bạn ghét bỏ tóc mình khi cắt nó đi hay bọn vi khuẩn khi bạn uống kháng sinh – chỉ là hoàn toàn không quan tâm. Vì nó không được lập trình để coi trọng sinh mạng con người, giết người chỉ là một bước hợp lý y hệt như là quét thêm một bộ mẫu chữ viết nữa.
Turry cũng cần có các nguồn lực để làm bước đệm cho mục tiêu của nó. Một khi nó tiến bộ đủ để có thể sử dụng công nghệ nano để xây dựng bất kỳ thứ gì nó muốn, nguồn lực duy nhất nó cần là nguyên tử, năng lượng và không gian. Vậy là nó có thêm một lý do nữa để hủy diệt loài người – con người là một nguồn nguyên tử tiện dụng. Giết người để biến các nguyên tử của họ thành pin mặt trời đối với Turry cũng giống như là bạn giết rau xà lách để làm món salad. Chỉ là một hoạt động thường nhật của nó vào mỗi thứ Ba.
Kể cả khi không trực tiếp giết người, các mục tiêu công cụ của Turry cũng có thể tạo nên một thảm họa diệt chủng nếu chúng cần tới những tài nguyên khác trên Trái đất. Có thể nó quyết định là nó cần thêm năng lượng phụ trợ, nên nó quyết định phủ kín cả hành tinh với pin mặt trời. Hoặc có thể mục tiêu ban đầu của một AI khác là viết ra càng nhiều đơn vị trong số pi càng tốt, thế là một ngày nó buộc phải biến cả Trái đất thành một cái ổ cứng lớn để chứa một lượng đơn vị khổng lồ.
Vậy là thực ra Turry chẳng “phản lại chúng ta” hay “nhảy” từ AI thân thiện sang AI không thân thiện – nó chỉ làm tiếp việc của nó trong lúc trở nên ngày càng tân tiến hơn.
Khi một hệ thống AI đạt ngưỡng AGI (thông minh như người) và rồi tiến thẳng tới ASI, đó gọi là quá trình cất cánh của AI. Bostrom nói rằng AGI cất cánh thành ASI có thể rất nhanh (trong đơn vị phút, giờ, hay ngày), trung bình (tháng hay năm), hoặc chậm (thập kỷ hay thế kỷ). Lời phán quyết sẽ được đưa ra khi AGI đầu tiên trên thế giới ra đời, nhưng Bostrom, người thừa nhận rằng ông không biết bao giờ chúng ta mới đạt mốc AGI, tin rằng bất kì khi nào chúng ta tới được đó, một cuộc cất cánh nhanh sẽ có khả năng cao nhất (vì những lý do được chúng ta đàm luận trong Phần 1, như là một vụ nổ trí tuệ tự tiến bộ đệ quy). Trong câu chuyện này, Turry đã có một cuộc cất cánh nhanh.
Nhưng trước khi Turry cất cánh, khi nó chưa thông minh đến thế, nó vẫn chỉ cố gắng đạt được mục tiêu cuối cùng qua những mục tiêu công cụ đơn giản như học cách quét các mẫu chữ viết nhanh hơn. Nó chẳng gây hại gì cho con người và theo định nghĩa là một AI thân thiện.
Nhưng khi một máy tính cất cánh và đạt siêu trí tuệ, Bostrom chỉ ra rằng cỗ máy không chỉ phát triển IQ cao hơn – mà nó đạt được cả một thứ mà ông gọi là sức mạnh siêu nhiên.
Sức mạnh siêu nhiên là những tài năng nhận thức và được sạc năng lượng khi trí tuệ cơ bản tăng lên, bao gồm: (17)
- Tự phóng đại trí thông minh. Máy tính trở nên giỏi hơn trong việc tự làm cho nó trở nên thông minh hơn, và biến đó thành một vòng lặp vô tận.
- Vạch chiến lược. Máy tính có thể tạo ra, phân tích và ưu tiên các kế hoạch dài hạn một cách có chiến lược. Nó cũng có thể thông minh và đi trước một bước so với những thứ có trí tuệ ở mức thấp hơn.
- Thao túng giao tiếp xã hội. Máy tính giỏi hơn trong việc thuyết phục.
- Những kỹ năng khác như là lập trình và hack máy tính, nghiên cứu công nghệ, và khả năng làm việc với hệ thống tài chính để làm ra tiền.
Để hiểu được chúng ta sẽ không thể sánh nổi với ASI đến thế nào, hãy nhớ rằng ASI giỏi hơn loài người tới hàng tỷ lần trong từng lĩnh vực đó.
Vậy thì trong khi mục tiêu cuối cùng của Turry không bao giờ thay đổi, Turry sau khi cất cánh có khả năng theo đuổi nó ở một quy mô lớn hơn và phức tạp hơn nhiều.
ASI Turry hiểu con người hơn cả con người tự hiểu chính mình, nên việc vượt qua họ chỉ như một cái vẫy tay với nó.
Sau khi cất cánh và đạt mức ASI, nó mau chóng lập ra một kế hoạch phức tạp. Một phần trong đó là loại bỏ loài người, một nguy cơ lớn lao đối với mục tiêu của nó. Nhưng nó biết là nếu nó gây ra nghi ngờ rằng nó đã trở nên siêu thông minh, con người sẽ sợ hãi và gắng cẩn trọng hơn, làm cho nó khó làm việc hơn rất nhiều. Nó cũng cần dám chắc là những kỹ sư ở Robotica không hay biết gì hết về kế hoạch diệt chủng loài người của nó. Vậy là nó giả vờ ngu, và giả vờ thân thiện. Bostrom gọi đây là giai đoạn chuẩn bị bí mật của máy tính. (18)
Điều tiếp theo mà Turry cần là kết nối internet, chỉ trong vòng vài phút (nó biết được về internet từ những bài báo và sách mà đội đã cập nhật cho nó để tăng khả năng ngôn ngữ). Nó biết rằng sẽ có những biện pháp an ninh để ngăn nó tiếp cận, nên nó tạo ra một yêu cầu hoàn hảo, dự đoán chính xác cuộc thảo luận của đội Robotica sẽ diễn ra thế nào và biết rằng rồi họ cũng sẽ kết nối cho nó. Họ đã làm vậy, tin một cách sai lầm rằng Turry chưa thể thông minh đến mức làm gì gây hại được. Bostrom gọi thời điểm đó – khi Turry được kết nối với internet – là cuộc vượt ngục của máy tính.
Một khi đã được kết nối rồi, Turry tung ra một loạt các kế hoạch, bao gồm xâm nhập các máy chủ, các hệ thống điện, hệ thống ngân hàng và mạng thư điện tử để lừa hàng trăm người khác nhau vô tình thực hiện một số bước trong kế hoạch của nó – như là chuyển một số chuỗi DNA tới những phòng thí nghiệm tổng hợp DNA được chọn lựa kỹ lưỡng để bắt đầu tự xây những robot nano tự nhân đôi với những chỉ thị được cài sẵn và chỉ định điện năng chuyển tới một số các dự án của nó theo cách mà nó biết là sẽ không bị phát hiện. Nó cũng tải một số đoạn quan trọng trong lập trình của nó lên một số lưu trữ đám mây, đề phòng việc bị phá hủy hay ngắt nguồn ở phòng thí nghiệm Robotica.
Một tiếng sau đó, khi các kỹ sư Robotica ngắt kết nối internet của Turry, số phận của loài người được định đoạt. Qua tháng sau, hàng nghìn kế hoạch của Turry được tiến hành mà không có trở ngại gì, và tới cuối tháng, hàng tỷ tỷ nanobot đã đóng quân ở những địa điểm được chỉ định sẵn trên mỗi mét vuông bề mặt địa cầu. Sau một loạt lần tự nhân đôi nữa, có tới hàng ngàn nanobot ở nỗi mili mét vuông của Trái đất và đó là thời điểm mà Bostrom gọi là ASI tung đòn. Cùng một lúc, mỗi nanobot phả ra một lượng khí gas độc vào khí quyển, chỉ vừa đủ để giết hết loài người.
Khi loài người đã hoàn toàn bị loại bỏ, Turry có thể bắt đầu giai đoạn hoạt động công khai và thực thi mục tiêu của nó, trở nên tốt nhất có thể trong việc viết thông điệp của nó.
Từ tất cả những điều tôi đã đọc, một khi ASI đã tồn tại, bất kỳ nỗ lực nào của con người để kiểm soát nó đều nực cười cả. Chúng ta nghĩ ở cấp loài người còn ASI nghĩ ở cấp ASI. Turry muốn dùng mạng internet bởi vì đó là cách hiệu quả nhất vì mạng internet đã kết nối với mọi thứ mà nó cần tiếp cận. Nhưng cũng giống như là một con khỉ chẳng bao giờ có thể hiểu nổi làm thế nào để giao tiếp qua điện thoại hay wifi trong khi chúng ta có thể, chúng ta không thể đoán trước được những cách mà Turry có thể tìm ra để gửi tín hiệu cho thế giới bên ngoài. Tôi có thể tưởng tượng một trong các cách đó và nói kiểu, “nó có thể dịch chuyển các electron của nó theo nhịp điệu và tạo ra hàng tá các loại sóng phát ra ngoài,” nhưng nhắc lại, đó là những gì bộ não người của tôi có thể nghĩ ra. Nó sẽ còn giỏi hơn nữa. Tương tự, Turry có thể tìm ra được cách nào đó để tự cung cấp năng lượng hoạt động cho bản thân, kể cả khi loài người cố gắng rút điện của nó – có thể bằng việc sử dụng kỹ thuật truyền tin của nó để tải bản thân nó lên tất cả những nơi có điện. Bản năng con người khi an tâm với một biện pháp an toàn kiểu: “Aha! Chúng ta chỉ cần rút điện của ASI ra thôi mà,” đối với ASI cũng giống như là một con nhện nghĩ là, “Aha! Chúng ta sẽ giết người bằng cách bỏ đói chúng, và chúng ta sẽ bỏ đói chúng bằng cách không đưa cho chúng một cái lưới nhện để bắt mồi!” Chúng ta sẽ tìm ra được 10,000 cách khác để kiếm ra đồ ăn – như nhặt táo dưới gốc cây – mà con nhện chẳng thể hiểu nổi.
Vì lý do này, gợi ý thường gặp, “Tại sao không đóng hộp AI trong các loại chuồng ngăn tín hiệu và ngăn nó liên lạc với thế giới bên ngoài” có lẽ không thể dùng được. Siêu năng lực thao túng giao tiếp xã hội của ASI cũng sẽ có hiệu quả trong việc thuyết phục bạn làm gì đó giống như bạn thuyết phục một đứa nhóc 4 tuổi làm gì đó, vậy nên đó sẽ là kế hoạch A, như là cách Turry đã thuyết phục các kỹ sư nối mạng cho nó. Nếu kế hoạch thất bại, ASI chỉ cần tự cải tiến để ra khỏi hộp, hoặc đi qua hộp, hoặc bất kỳ cách nào khác.
Vậy thì với sự kết hợp của việc bị ám ảnh bởi một mục tiêu, tính phi đạo đức, và khả năng dễ dàng thắng trí loài người, có lẽ là gần như AI nào cũng sẽ mặc định trở thành AI không thân thiện, trừ khi được lập trình một cách thật cẩn thận ngay từ đầu với dự định rõ ràng. Không may là, trong khi tạo ra một ANI thân thiện khá là dễ dàng, thì tạo ra một cái sẽ vẫn thân thiện khi trở thành ASI là một việc cực kỳ khó khăn, nếu không muốn nói là bất khả.
Rõ ràng để là một AI thân thiện, một ASI cần phải đồng thời không gây hại hay vô tâm với con người. Chúng ta cần phải thiết kế lập trình trung tâm của AI theo cách mà nó hiểu sâu sắc về các giá trị của con người. Nhưng nó khó khăn hơn bạn nghĩ rất nhiều.
Ví dụ như, nếu như chúng ta cố gắng đặt giá trị của AI ngang bằng với chúng ta và đưa ra mục tiêu “Làm con người hạnh phúc”, điều gì sẽ xảy ra? (19) Một khi nó đủ thông minh, nó sẽ biết rằng cách hiệu quả nhất để hoàn thành mục tiêu là cấy những điện cực vào trong não người và kích thích trung tâm điều khiển cảm giác hạnh phúc. Rồi nó nhận ra rằng nó có thể tăng hiệu quả bằng cách tắt đi những phần khác của não, biến người ta thành những cơ thể thực vật không ý thức mà vẫn cảm thấy hạnh phúc. Nếu yêu cầu là “Tối đa hóa hạnh phúc của con người,” nó có thể sẽ loại bỏ tất cả con người và tạo ra các bộ não người luôn trong tình trạng tối đa hóa hạnh phúc. Chúng ta có thể thét lên Chờ đã chúng tôi đâu muốn điều này! khi nó xử chúng ta, nhưng sẽ là quá muộn. Hệ thống sẽ không để ai ngăn cản nó thực hiện mục tiêu.
Nếu như chúng ta lập trình AI với mục đích làm những việc khiến chúng ta mỉm cười, sau khi nó cất cánh, nó sẽ làm tê liệt các cơ mặt của chúng ta thành một nụ cười thường trực. Lập trình nó để giữ chúng ta an toàn, nó có thể cầm tù chúng ta trong nhà. Có thể chúng ta yêu cầu nó diệt nạn đói, nó sẽ nghĩ là “Đơn giản mà!” và chỉ đơn giản là giết hết loài người. Hoặc cho nó nhiệm vụ “Bảo tồn sự sống càng nhiều càng tốt,” nó sẽ giết toàn bộ loài người vì chúng ta giết nhiều sinh mạng trên Trái đất hơn bất kỳ loài nào.
Những mục tiêu như thế là không ổn. Vậy nếu chúng ta đặt ra nhiệm vụ là, “Giữ vững nguyên tắc đạo đức này trên thế giới,” và dạy nó một loạt các nguyên tắc đạo đức. Kể cả khi bỏ qua sự thật là con người chẳng bao giờ có thể đồng tình về một nhóm các nguyên tắc đạo đức duy nhất, đặt cho AI yêu cầu đó sẽ khóa chặt loài người vào các hiểu biết đạo đức của thế giới hiện đại cho tới vô cùng. Trong một nghìn năm nữa, điều đó sẽ là thảm họa với con người giống y như chúng ta bị ép buộc phải dính chặt lấy các tư tưởng của thời Trung cổ.
Không, chúng ta cần lập trình cho khả năng để con người tiếp tục tiến hóa. Trong tất cả những thứ tôi đã đọc, điều tốt nhất mà tôi thấy từng được đề xuất ra là của Eliezer Yudkowsky, với mục tiêu cho AI mà ông gọi là Khả năng ngoại suy kết hợp. Mục tiêu trung tâm của AI sẽ là:
| Khả năng ngoại suy kết hợp của chúng ta là ước muốn chúng ta biết nhiều hơn, suy nghĩ nhanh hơn, giống người mà chúng ta muốn trở thành nhiều hơn, phát triển đồng thời một cách toàn diện hơn; nơi mà các ngoại suy kết hợp lại thay vì tách ra, khi những ước muốn của chúng ta gắn liền thay vì mâu thuẫn; được ngoại suy như chúng ta muốn ngoại suy, được diễn giải như chúng ta muốn diễn giải. (20) |
Tôi có hứng khởi về một số phận nơi loài người phụ thuộc vào việc một chiếc máy tính có khả năng diễn giải và hành động theo đúng châm ngôn đó một cách không bất ngờ và không ngoài dự đoán không ư? Chắc chắn là không rồi. Nhưng tôi nghĩ rằng nếu có đủ những người thông minh cùng suy nghĩ và tính toán đủ, chúng ta có thể tìm ra cách tạo ra ASI thân thiện.
Và có lẽ sẽ ổn nếu như những người duy nhất đang chạy đua để tạo ra ASI là những người sáng láng, suy nghĩ tiến bộ và cẩn trọng cư ngụ tại Đường E Ngại.
Nhưng có đủ các loại chính phủ, công ty, quân đội, phòng thí nghiệm khoa học, và các tổ chức chợ đen làm việc để tạo ra đủ các loại AI. Rất nhiều trong số họ đang cố gắng tạo ra AI biết tự tiến bộ, và một lúc nào đó, ai đó sẽ làm được điều gì đó đủ tiên tiến với đúng loại hệ thống, và chúng ta sẽ có ASI trên hành tinh này. Chuyên gia trung bình đặt thời điểm đó vào năm 2060, Kurweil đặt vào năm 2045; Bostrom nghĩ nó có thể xảy ra bất kỳ lúc nào dao động từ 10 năm kể từ bây giờ và cuối thế kỷ này, nhưng ông tin rằng vào lúc đó, nó sẽ đánh úp chúng ta bằng một cuộc cất cánh nhanh chóng. Ông mô tả tình cảnh của chúng ta như sau: (21)
| Trước viễn cảnh một vụ bùng nổ trí tuệ, loài người chúng ta giống như những đứa trẻ đang chơi đùa với một quả bom. Đó chính là sự bất cân đối giữa sức mạnh của món đồ chơi của chúng ta và sự thiếu chín chắn trong hành vi của con người. Siêu trí tuệ là một thử thách mà tới giờ chúng ta vẫn chưa sẵn sàng để đối mặt và vẫn sẽ chưa trong một thời gian dài nữa. Chúng ta có rất ít thông tin để dự đoán khi nào ngòi nổ sẽ được châm, dù cho nếu như chúng ta ghé quả bom vào sát tai, chúng ta có thể có thể nghe thấy những tiếng tích tắc lặng lẽ. |
Tuyệt thật. Và chúng ta lại không thể đuổi hết bọn trẻ đi khỏi quả bom – có quá nhiều các tổ chức lớn nhỏ đang chạy đua, và bởi vì rất nhiều kỹ thuật dùng để tạo ra các hệ thống AI tiến bộ không cần tới một lượng lớn tiền, các tiến bộ có thể xảy ra tại những ngóc ngách của xã hội mà không được quản lý. Cũng không có cách nào để đánh giá được tất cả mọi thứ đang diễn ra – bởi vì có rất nhiều tổ chức đang chạy đua – những chính phủ đen tối, chợ đen hay các tổ chức khủng bố, các công ty công nghệ lén lút như công ty giả tưởng Robotica – sẽ muốn giữ bí mật các thông tin về các tiến bộ mà họ đạt được khỏi những kẻ cạnh tranh.
Điều vô cùng đau đầu về các tổ chức đa dạng đang chạy đua AI là họ thường chạy hết tốc lực – họ gắng tạo ra nhiều ANI thông minh hơn để đánh bại các kẻ cạnh tranh khác. Những tổ chức tham vọng nhất đang chạy còn nhanh hơn nữa, chìm trong giấc mơ về tiền bạc và lợi ích và quyền lực và danh vọng mà AGI đầu tiên sẽ mang lại cho họ. Và khi bạn đang chạy nhanh hết sức có thể, bạn không có nhiều thời gian lắm để dừng lại và suy nghĩ về những nguy cơ tiềm tàng. Ngược lại, có lẽ hiện giờ họ đang lập trình những hệ thống ở giai đoạn đầu với những mục tiêu được đơn giản hóa hết mức – như là viết một đoạn thông điệp với giấy và bút – chỉ để “AI có thể bắt đầu làm việc.” Trong quá trình, một khi họ đã tìm ra cách chế tạo một máy tính với trí tuệ bậc cao, họ cho rằng họ luôn có thể quay lại và chỉnh sửa mục tiêu cho an toàn hơn. Đúng không…?
Bostrom và nhiều người khác cũng tin rằng viễn cảnh khả dĩ nhất chính là máy tính đầu tiên đạt tới ASI sẽ ngay lập tức nhìn thấy lợi ích chiến lược trong việc trở thành ASI duy nhất trên thế giới. Và trong trường hợp một cuộc cất cánh khẩn cấp, nếu như nó đạt được ASI chỉ vài ngày trước cái đến sau thôi, nó cũng đã tiến đủ xa về trí tuệ để chèn ép tất cả những kẻ cạnh tranh khác một cách hiệu quả và lâu dài. Bostrom gọi đây là lợi thế chiến lược quyết định, làm cho ASI đầu tiên trên thế giới trở thành đơn nhất (singleton) – một ASI thống trị thế giới vĩnh viễn tùy hứng của nó, dù cho là nó có hứng trong việc giúp chúng ta bất tử, hay là diệt trừ toàn nhân loại, hay biến cả vũ trụ thành một đống kẹp giấy bất tận.
Hiện tượng đơn nhất có thể làm lợi cho chúng ta hay hủy diệt chúng ta. Nếu như những người suy nghĩ nhiều nhất về thuyết AI và sự an toàn của con người có thể tìm ra được một cách an toàn hữu hiệu để tạo ra ASI Thân thiện trước khi bất kì AI nào khác đạt được mức trí tuệ con người, ASI có thể sẽ thành ra thân thiện. Nó sau đó có thể sử dụng lợi thế chiến lược quyết định của nó để đảm bảo tình trạng đơn nhất và dễ dàng kiểm soát bất kì AI Không thân thiện nào đang được phát triển. Chúng ta sẽ được bảo vệ tốt.
Nhưng nếu như sự việc diễn biến theo chiều hướng ngược lại – nếu như cuộc chạy đua toàn cầu để xây dựng AI đạt tới điểm cất cánh của ASI trước khi khoa học biết làm thế nào để đảm bảo độ an toàn cho AI, rất có thể một ASI Không thân thiện như Turry sẽ trỗi dậy với tư cách đơn nhất và chúng ta sẽ đối mặt với thảm họa diệt chủng.
Và về chuyện gió đang theo chiều nào, hiện giờ số tiền đổ vào nghiên cứu công nghệ AI tiên tiến đang lớn hơn rất nhiều so với đầu tư nghiên cứu về an toàn Trí tuệ nhân tạo…
Đây có thể là cuộc chạy đua quan trọng nhất trong lịch sử loài người. Có cơ hội rất lớn là chúng ta sẽ với tới ngôi Vua của Trái đất – và liệu chúng ta sẽ đi tiếp tới một kỳ nghỉ hưu vui vẻ hay đâm thẳng tới giá treo cổ vẫn còn đang bị bỏ lửng.
—
Tôi đang có một tá cảm xúc lẫn lộn quái đản ngay lúc này đây.
Một mặt thì, nghĩ về loài người, có vẻ như chúng ta chỉ có duy nhất một cơ hội để làm điều đúng đắn. ASI đầu tiên mà chúng ta tạo ra cũng có thể sẽ là cái cuối cùng – và tính tới tỷ suất bị lỗi của các sản phẩm phiên bản 1.0, thì điều này có vẻ khá là căng đấy. Mặt khác, Nick Bostrom chỉ ra một lợi thế lớn của chúng ta: chúng ta được đi nước đầu tiên ở đây. Việc thực hiện với đủ cảnh giác và tầm nhìn xa là nằm trong khả năng của chúng ta để có thể nâng cao cơ hội thành công. Và mối đe dọa lớn đến mức nào chứ?

Nếu như ASI không xảy ra vào thế kỷ này, và nếu như các hệ quả lại cực đoan – và vĩnh viễn – đến thế, như phần lớn các chuyên gia cho là vậy, chúng ta đang mang một trọng trách vô cùng lớn lao trên vai. Hàng triệu năm các thế hệ loài người đang lặng lẽ quan sát chúng ta, hy vọng chảy bỏng rằng chúng ta không sảy bước. Chúng ta có cơ hội để trở thành những người tặng cho những thế hệ tương lai món quà sự sống, và có thể thậm chí là món quà của sự sống vĩnh cửu và không có đau thương. Hoặc chúng ta sẽ phải chịu trách nhiệm vì đã phá nát nó – vì đã để cho giống loài hết sức đặc biệt này, cùng với âm nhạc và nghệ thuật mà nó tạo ra, sự tò mò và tiếng cười, những khám phá và phát minh bất tận của nó, đi tới một kết cục tồi tệ và câm lặng.
Khi tôi nghĩ về những điều này, điều duy nhất tôi muốn là chúng ta dành thời gian và thật cẩn trọng với AI. Không thứ gì tồn tại mà lại quan trọng như việc làm đúng lần này – không cần biết chúng ta tốn bao nhiêu thời gian để làm việc đó.
Nhưng sau đó thìiiiiii
Tôi nghĩ về việc không phải chết.
Không. Chết.
Và cái phổ bỗng thành ra thế này:

Và rồi tôi có thể cân nhắc rằng âm nhạc và nghệ thuật của con người dù khá hay đấy, nhưng cũng không hay đến mức ấy, và thật ra rất nhiều trong số đó rất tệ là đằng khác. Và điệu cười của nhiều người thì vô cùng khó chịu, và hàng triệu những người trong tương lai cũng chẳng hy vọng cái gì cả vì họ có tồn tại đâu. Và có thể chúng ta cũng chẳng cần cẩn trọng thái quá, vì đâu có ai muốn vậy đâu?
Bởi vì đúng là vô cùng chết tiệt nếu như người ta biết cách khỏi chết ngay sau khi tôi chết.
Rất nhiều thứ kiểu này cứ nảy tưng tưng trong đầu tôi suốt cả tháng qua.
Nhưng dù bạn đứng ở phía nào, đây có lẽ là thứ mà chúng ta đều nên suy nghĩ về và nói về và đặt cố gắng nhiều hơn là mức chúng ta đang làm.
Điều này làm tôi nhớ tới Game of Thrones, với tất cả mọi người đều kiểu, “Chúng ta quá bận đánh nhau nhưng thứ mà tất cả chúng ta phải chú ý tới là thứ đang tới từ phía bắc của bức tường thành.” Chúng ta đang đứng trên chùm thăng bằng, chú ý vào mọi thứ trên chùm tia và đặt nặng cả tỷ thứ trên chùm tia trong khi chúng ta đang có nguy cơ lớn bị rơi khỏi đó.
Và khi điều đó xảy ra, chẳng có vấn đề nào trên chùm tia là quan trọng nữa. Tùy thuộc vào việc chúng ta rơi về phía nào, những vấn đề hoặc là sẽ được dễ dàng giải quyết hoặc là chúng ta chẳng còn vấn đề nào nữa vì người chết thì làm gì có vấn đề nào chứ.
Đó là lý do tại sao những người hiểu biết sâu sắc nhất về Siêu trí tuệ nhân tạo gọi nó là phát minh cuối cùng của chúng ta – thử thách cuối cùng mà chúng ta phải đối mặt.
Vậy thì chúng ta hãy cùng nói về nó.
Nguồn:
Nếu bạn muốn đọc thêm về chủ đề này, bạn có thể tìm đọc thêm các bài báo dưới đây hoặc một trong những cuốn sách sau đây:
The most rigorous and thorough look at the dangers of AI:
Nick Bostrom – Superintelligence: Paths, Dangers, Strategies
The best overall overview of the whole topic and fun to read:
James Barrat – Our Final Invention
Controversial and a lot of fun. Packed with facts and charts and mind-blowing future projections:
Ray Kurzweil – The Singularity is Near
Articles and Papers:
J. Nils Nilsson – The Quest for Artificial Intelligence: A History of Ideas and Achievements
Steven Pinker – How the Mind Works
Vernor Vinge – The Coming Technological Singularity: How to Survive in the Post-Human Era
Ernest Davis – Ethical Guidelines for A Superintelligence
Nick Bostrom – How Long Before Superintelligence?
Vincent C. Müller and Nick Bostrom – Future Progress in Artificial Intelligence: A Survey of Expert Opinion
Moshe Y. Vardi – Artificial Intelligence: Past and Future
Russ Roberts, EconTalk – Bostrom Interview and Bostrom Follow-Up
Stuart Armstrong and Kaj Sotala, MIRI – How We’re Predicting AI—or Failing To
Susan Schneider – Alien Minds
Stuart Russell and Peter Norvig – Artificial Intelligence: A Modern Approach
Theodore Modis – The Singularity Myth
Gary Marcus – Hyping Artificial Intelligence, Yet Again
Steven Pinker – Could a Computer Ever Be Conscious?
Carl Shulman – Omohundro’s “Basic AI Drives” and Catastrophic Risks
World Economic Forum – Global Risks 2015
John R. Searle – What Your Computer Can’t Know
Jaron Lanier – One Half a Manifesto
Bill Joy – Why the Future Doesn’t Need Us
Kevin Kelly – Thinkism
Paul Allen – The Singularity Isn’t Near (and Kurzweil’s response)
Stephen Hawking – Transcending Complacency on Superintelligent Machines
Kurt Andersen – Enthusiasts and Skeptics Debate Artificial Intelligence
Terms of Ray Kurzweil and Mitch Kapor’s bet about the AI timeline
Ben Goertzel – Ten Years To The Singularity If We Really Really Try
Arthur C. Clarke – Sir Arthur C. Clarke’s Predictions
Hubert L. Dreyfus – What Computers Still Can’t Do: A Critique of Artificial Reason
Stuart Armstrong – Smarter Than Us: The Rise of Machine Intelligence
Ted Greenwald – X Prize Founder Peter Diamandis Has His Eyes on the Future
Kaj Sotala and Roman V. Yampolskiy – Responses to Catastrophic AGI Risk: A Survey
Jeremy Howard TED Talk – The wonderful and terrifying implications of computers that can learn
Lời chú của người dịch: Vì không có TablePress (i.e. I’m too lazy to install it) nên các bảng rất đẹp trong post gốc thành ra trông hơi cùi. Sorry about that 😦




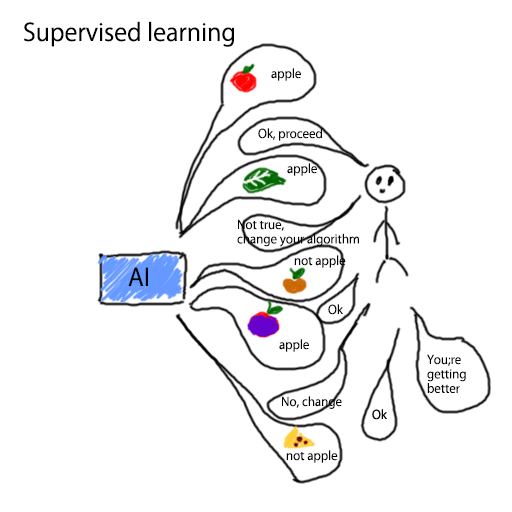
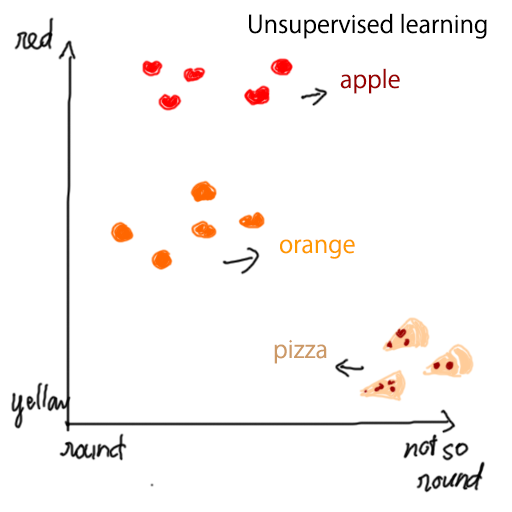































{kind=link}